Универсальная
система обработки потоков данных: устройство и принцип действия.
Поздняков Вадим Александрович,
аспирант Московского физико-технического
института (государственного университета),
ФГУП «Институт точной механики и
вычислительной техники им. С. А. Лебедева Российской академии
наук».
Концепция универсальной системы обработки потоков данных.
При
взаимодействии различных устройств обработки данных через каналы связи могут
использоваться достаточно сложные процедуры. Как правило, эти процедуры разбиваются
на ряд относительно простых и независимых друг от друга задач, которые, в свою
очередь, можно отнести к тому или иному уровню взаимодействия, в зависимости от
типа обработки данных. Одной из наиболее известных и общих моделей, описывающей
многоуровневое структурирование задач обработки, является эталонная модель взаимодействия
открытых систем (см. [1, 2]). В рамках этой модели каждая из взаимодействующих
систем разбивается на семь уровней.
Задачи
обработки, выполняемые на этих уровнях модели OSI, можно условно разделить на
три типа: задачи низкоуровневой, среднеуровневой и высокоуровневой обработки (рис. 1). Границы между этими типами размыты и могут меняться
в зависимости от конкретных стеков протоколов. Низкоуровневая обработка данных
выполняется на физическом (первом) и частично на канальном уровне. Ее
особенностями являются высокие требования к производительности обработчиков
(поэтому их всегда стараются реализовать аппаратно), достаточно низкая частота появления
новых алгоритмов обработки и модернизации уже существующих. Низкоуровневая
обработка (в случае приема данных — демодуляция, снятие помехоустойчивых кодов
и т. п.) заканчивается там, где появляется поток данных с байтовой (намного
реже — с битовой) структурой, в котором отсутствует избыточность (такая как код
Рида-Соломона), призванная обеспечить надежность передачи данных по физическому
каналу. Примерами подобных потоков являются последовательности транспортных
пакетов MPEG-2, кадров Ethernet, ячеек ATM.
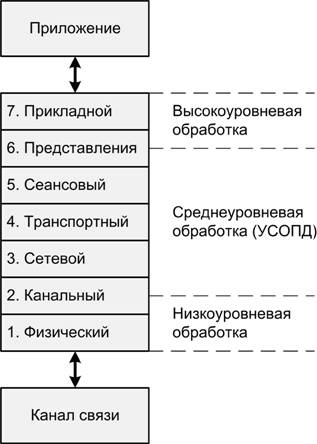
Рис. 1.
Место УСОПД в модели OSI.
Высокоуровневая
обработка начинается с уровня представления или с прикладного уровня, когда
возникает необходимость, как и в случае с низкоуровневой обработкой, применять
сложные и требовательные к производительности алгоритмы (декомпрессия,
дешифрование) или же осуществлять работу с большими массивами данных (контроль
прав пользователя, преобразование кодировок, протоколы со сложной системой
команд).
Среди
задач, относящихся к среднему уровню обработки, — контроль ошибок, управление
потоком, демультиплексирование, маршрутизация. Здесь используются относительно
несложные алгоритмы для обработки простых наборов команд (протокол HDLC), анализа
данных (обработка полей в заголовках пакетов), изменения байтовой структуры
потока (склейка сообщений из их частей) и т. п. В отличие от высокоуровневой
обработки, где часто используются сложные и очень разнообразные по своей
структуре и методам алгоритмы, реализации задач среднеуровневой обработки отличаются
друг от друга не так сильно.
Современное
состояние в индустрии оборудования и программного обеспечения для передачи данных
характеризуется большим разнообразием протоколов передачи и систем для их
обработки. В связи с этим производителям часто бывает выгодно придерживаться трех
принципов — мультиплатформенность, многофункциональность и гибкость. Первый из
них подразумевает возможность использования одних и тех же алгоритмов обработки
данных на как можно большем числе платформ. Это позволяет уменьшить время и
стоимость разработки алгоритмов для всего ряда предлагаемых производителем
решений. Типичный пример — приложения на языке Java для сотовых телефонов.
Суть
второго принципа заключается в том, что одну и ту же платформу можно
использовать для выполнения большого числа различных задач. В случае с
передачей данных это означает поддержку нескольких стеков протоколов и,
возможно, нескольких способов работы с каждым из них. Третий принцип — гибкость
— требует от системы возможности перенастраиваться в достаточно широких
пределах. Это необходимо в первую очередь для оперативного обновления системы,
если какой-либо из поддерживаемых протоколов был изменен. Разумеется, сам
процесс модернизации системы не должен быть слишком трудоемким.
Преимущества
создания мультиплатформенных, многофункциональных и гибких продуктов очевидны,
однако при их разработке возникают трудности. Они связаны с тем, что,
во-первых, не существует общедоступных стандартов, регламентирующих структуру и
функционирование универсальных систем, особенности которых описаны выше.
Во-вторых, при текущем уровне производительности вычислительной техники многие
задачи обработки (в первую очередь низкоуровневые и часть высокоуровневых) необходимо
реализовывать аппаратно — быстродействия гораздо более гибких программных
аналогов часто оказывается недостаточно. В-третьих, даже если вся программная
часть обработки удачно реализуется с учетом вышеупомянутых принципов, то это,
как правило, делается на высокоуровневом языке программирования (C/C++), что, в
свою очередь, требует создания набора инструментальных средств разработки, привлечения
для разработки и обновления системы опытных программистов, которые, кроме всего
прочего, должны хорошо разбираться в принципах передачи данных.
Все
это значительно увеличивает расходы на разработку и поддержку, что может свести
на нет выгоду от универсализации. Один из возможных выходов — создание
достаточно простой в реализации (как программной, так и программно-аппаратной)
системы, которая позволяла бы осуществлять как минимум среднеуровневую обработку,
используя алгоритмы, написанные на весьма простом языке, специально предназначенном
для описания задач обработки данных. Именно о такой системе и пойдет речь далее
в этой статье.
Универсальная
система обработки потоков данных (УСОПД) осуществляет обработку потоков данных
на входе согласно загруженным в нее алгоритмам и на выходе формирует потоки
данных, представляющие собой результаты этой обработки. УСОПД с загруженными
алгоритмами обработки будем называть универсальным обработчиком (УО),
подразумевая под словом «универсальный» то, что обработчик реализован с помощью
универсальной системы.
Способы применения.
На
рис.
2 представлены некоторые способы применения
универсальных обработчиков. Наиболее общий вариант реализации двухстороннего
взаимодействия приложения с каналом связи изображен на рис. 2, а. Поток данных последовательно проходит через
низкоуровневые обработчики (НУ), среднеуровневые (УО на основе УСОПД) и
высокоуровневые обработчики (ВУ) в обоих направлениях.
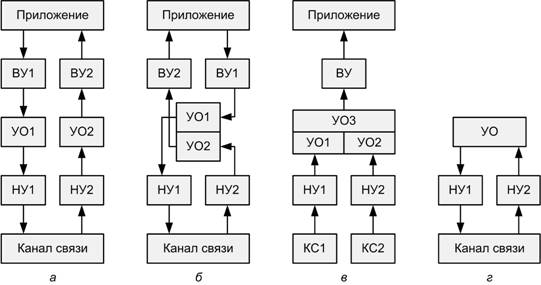
Рис. 2.
Различные способы применения
универсальных обработчиков:
а)
прием и передача данных;
б)
прием и передача с использованием одного УО;
в)
прием нескольких сигналов с различной низкоуровневой обработкой;
г)
низкоуровневое сетевое устройство.
Если
производительности УСОПД достаточно, то в некоторых случаях двухстороннее
взаимодействие целесообразнее реализовывать, объединив УО1 и УО2 в один
обработчик (рис.
2, б). Иногда возникает необходимость принимать
несколько сигналов, отличающихся низкоуровневой обработкой, и объединять их в
общий поток на высоких уровнях. Реализация подобной задачи показана на рис. 2, в.
Существует
целый ряд устройств, работающих с каналами связи, в которых полностью
отсутствует высокоуровневая обработка (например, сетевые маршрутизаторы). На рис. 2, г, изображено такое устройство, построенное на
основе УО. Разумеется, сфера применения УО не ограничивается этими четырьмя примерами.
Среди других возможных применений — проверка потоков на соответствие стандартам,
генерация тестовых сигналов и т. д.
Архитектура.
Как
уже было упомянуто выше, алгоритмы для УСОПД должны быть написаны на
специализированном языке обработки данных (обсуждение особенностей такого языка
выходит за рамки статьи). В свою очередь, для обеспечения эффективного выполнения,
программы на этом языке должны быть предварительно скомпилированы в байт-код
(последовательность команд и служебных полей, см. [3]). Основной частью
УСОПД является виртуальная машина (ВМ), которая транслирует байт-код в команды
той среды, частью которой является УСОПД.
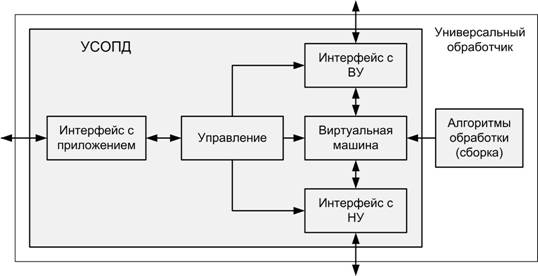
Рис. 3.
Функциональная схема УО.
На
рис.
3 приведена функциональная схема УО. ВМ обменивается
данными с низкоуровневыми и высокоуровневыми обработчиками через
соответствующие интерфейсы. Кроме того, в УСОПД должен присутствовать интерфейс
с приложением для передачи управляющих команд (например, перезапуск системы или
загрузка других алгоритмов обработки).
Логически
УО устроен по принципу крупномодульного потокового программирования (large-grain
dataflow, см. [4]): весь процесс обработки разбивается на достаточно простые
задачи, выполняемые отдельными модулями (пример УО показан на рис. 4). Модуль — функциональная единица, выполняющая обработку
входных данных и формирующая на основе результатов этой обработки выходные
данные. Каждому модулю соответствует несколько байт-кодов (рис. 5).
Коды
инициализации всех модулей, входящих в состав обработчика, выполняются перед
началом обработки. Они служат для установки начальных состояний модулей.
Каждому
входному потоку модуля соответствует свой код обработки. Эти коды должны
выполняться последовательно для всех входов модуля. Если за время, прошедшее с
момента предыдущего выполнения кода обработки входного потока, в этом потоке не
появилось новых элементов данных (см. ниже), то соответствующий код не
выполняется, в противном случае код выполняется для каждого нового элемента данных.
Если один и тот же поток является входным для нескольких модулей, все элементы
данных удаляются из него только после того, как отработают все эти модули.
Когда
все коды обработки входов выполнены, должен быть выполнен итоговый код. Он
используется в том случае, если необходимо обобщить результаты обработки
различных входных потоков. Запись данных в выходные потоки производится в процессе
выполнения кодов обработки. Следует заметить, что ни один из вышеописанных
кодов не является обязательным.
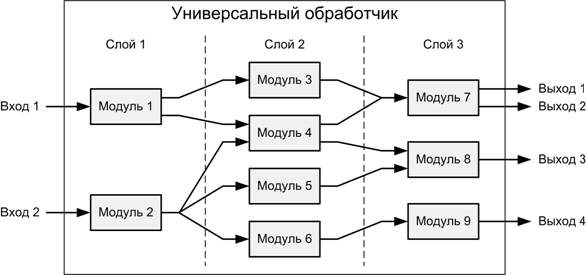
Рис. 4.
Логическое устройство УО.
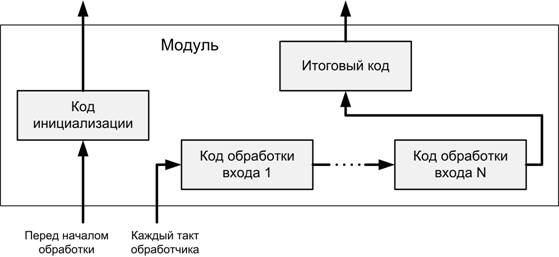
Рис. 5.
Коды модуля и порядок их выполнения.
Передача
данных между модулями, входящими в состав УО, а также ввод исходных данных в УО
и вывод результатов осуществляется с помощью потоков, состоящих из элементов
данных (рис.
6).
Элемент
данных — единица обмена информацией между модулями. Фактически представляет
собой массив байтов (с заданным размером), в котором последовательно записан
некоторый набор значений. Тип (и, соответственно, размер в байтах) каждого
значения определяется модулем, который порождает элементы данных и помещает их
в выходной поток.
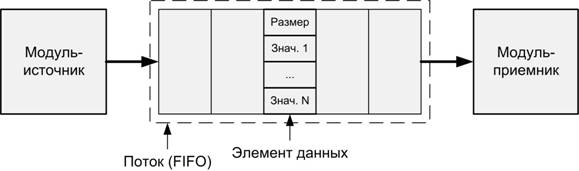
Рис. 6.
Передача данных между модулями.
Тип
элемента данных определяется порядком следования значений и их типами. Он
называется совместимым с входом модуля, если модуль обрабатывает все значения,
передаваемые в элементе, или некоторые из них, используя при этом верные типы и
размеры значений. Например, если модуль ожидает на один из входов элементы данных,
состоящие из двух 32-разрядных целых чисел, то элементы данных, состоящие из
трех 32-разрядных целых чисел, будут совместимыми с этим входом (модуль просто
не будет обрабатывать последнее значение), а элементы данных, состоящие из
одного 32-разрядного целого и одного 8-разрядного целого, будут несовместимы
(модуль не сможет корректно прочесть последнее значение, так как ожидает число
другой разрядности). Не допускается подача на вход модуля потока элементов
данных несовместимого типа — результат будет непредсказуем.
Поток
— последовательность элементов данных, выполняет функцию буфера для передачи
данных между модулями. Реализуется в виде очереди (FIFO), в конец которой добавляются элементы данных, порождаемые
модулями-источниками (порядок записи элементов данных в поток не имеет особого
значения). Один или несколько модулей-приемников получают элементы данных из
начала очереди. Элементы данных удаляются из потока только после того, как их
получат все модули, принимающие данный поток. Существует особый тип потоков,
которые содержат только один элемент данных. Фактически такие потоки являются
переменными (или наборами переменных), значения которых обновляются в процессе
обработки. Все данные, которые подаются на вход УО, должны быть преобразованы в
потоки элементов данных — это задача УСОПД.
Слой
— группа модулей (см. рис.
4). Слои служат для задания последовательности запуска
модулей в УО, а также для логического разделения модулей на группы по
функциональному назначению (например, по принадлежности к уровням модели OSI). Модули, находящиеся в одном слое, не могут быть
связаны друг с другом потоками, и, следовательно, не обмениваются данными и
могут выполняться параллельно или в произвольной последовательности (в
зависимости от реализации УО). Переход к выполнению модулей в следующем слое
происходит только после того, как отработают все модули из предыдущего слоя. Модуль-источник
по отношению к модулю-приемнику всегда должен находиться в слое, обрабатываемом
раньше — это гарантирует отсутствие петель, которые могут привести к зависанию
УО.
Сборка
— совокупность модулей и связывающих их потоков данных. Фактически сборка
представляет собой общий алгоритм обработки. Сборка должна иметь как минимум один
вход: на вход модуля в первом слое должен подаваться поток элементов данных
извне. В качестве результатов обработки выступают потоки данных, не имеющие
модулей-приемников, а также любые другие потоки между модулями внутри сборки,
если это необходимо в целях отладки.
Файл,
в котором хранятся данные о конкретной сборке, должен содержать общую
информацию о сборке, а также подробные описания модулей, потоков и их взаимосвязей.
Подробное рассмотрение форматов этих описаний выходит за рамки данной статьи,
поэтому ограничимся лишь общими сведениями.
Описание
модуля содержит общую информацию о нем (название, версия и т. п.), а также семь
областей: переменные, параметры (переменные с начальным значением), входные
потоки, выходные потоки, код инициализации, итоговый код и коды обработки
входных потоков. Описание потока содержит информацию о полях элементов данных
этого потока, модулях-источниках и модулях-приемниках. Потокам, модулям, переменным
и параметрам соответствуют уникальные числовые идентификаторы.
Алгоритм работы.
Итак,
сначала пользователь создает отдельные модули, затем компонует из них сборку,
эта сборка загружается в УСОПД, которую необходимо настроить надлежащим
образом, и универсальный обработчик готов к выполнению возложенных на него функций.
Рассмотрим
алгоритм работы УСОПД. Ниже приведены основные операции, выполняемые универсальной
системой перед началом обработки и за каждый ее такт:
1.
Инициализация.
1.1. Размещение переменных и параметров в памяти.
1.2. Установка начальных значений параметров.
1.3. Построение таблицы соответствия идентификаторов
потоков для каждого модуля.
1.4. Выполнение кодов инициализации каждого модуля.
2.
Такт обработки.
2.1. Загрузка новых элементов данных во входные потоки
сборки.
2.1.1. Копирование новых элементов данных.
2.1.2. Задание количества новых элементов данных для каждого
потока.
2.1.3. Установка счетчика приемников для каждого потока.
2.2. Запуск каждого модуля сборки (в определенном порядке).
2.2.1. Обработка каждого входа модуля.
2.2.1.1.Установка указателя текущего элемента данных на начало
потока.
2.2.1.2.Обработка каждого элемента данных.
2.2.1.2.1. Копирование полей в соответствующие переменные.
2.2.1.2.2. Запуск кода обработки.
2.2.1.2.3. Перемещение указателя на следующий элемент.
2.2.1.3.Уменьшение счетчика приемников потока на 1.
2.2.2. Обработка выхода модуля (при выполнении
соответствующей команды).
2.2.2.1.Установка счетчика приемников (при первом обращении).
2.2.2.2.Копирование переменных в поля элемента данных.
2.2.2.3.Перемещение указателя на следующий элемент.
2.2.3. Выполнение итогового кода.
2.2.4. Очистка потоков, у которых счетчик приемников равен 0.
2.3. Выгрузка элементов данных из выходных потоков сборки
2.3.1. Копирование элементов данных.
2.3.2. Очистка потоков.
Перед
началом обработки для каждого модуля УСОПД должна построить таблицы
соответствия между идентификаторами потоков модулей и идентификаторами межмодульных
потоков сборки (операция 1.3), так как в командах байт-кодов указываются
идентификаторы потоков модулей, а УСОПД оперирует с собственными идентификаторами
потоков.
Операция
2.1.3 предусматривает присваивание счетчику приемников для каждого входного
потока значения, равного общему числу приемников этого потока. В процессе
обработки (операция 2.2.1.3) этот счетчик уменьшается на 1, как только будет
выполнен очередной модуль с этим потоком на входе. Когда будут выполнены все модули,
счетчик станет равным 0, т. е. данные, содержащиеся в потоке, станут ненужными
для дальнейшей обработки и их можно будет удалить из оперативной памяти (операция
2.2.4). Исключением являются потоки, представляющие собой обновляемые элементы
данных.
Операция
2 (такт обработки) выполняется циклически, условием очередного запуска является
поступление на какой-либо из входов УО достаточного количества новых элементов
данных. Процесс обработки может быть остановлен в любой момент времени самим УО
(например, при возникновении критической ошибки) или пользователем.
Заключение.
Рассмотренная
в данной статье система является достаточно удобным многофункциональным инструментом,
который может являться частью как программных, так и программно-аппаратных
решений, требующих возможности изменения алгоритмов среднеуровневой обработки
данных без вмешательства во внутреннее устройство обработчика. Одни и те же
алгоритмы обработки могут быть использованы на разных платформах. Кроме того,
обеспечивается возможность быстрой модификации самих алгоритмов и, за счет
модульной структуры, упрощается повторное использование их частей.
От
других подобных систем УСОПД отличается сравнительной простотой реализацией для
конкретной платформы, кроме того, она оптимизирована непосредственно для
потоковой обработки телекоммуникационных протоколов (ранее таких систем не существовало).
Литература.
1.
ISO/IEC 7498-1: Information technology — Open Systems
Interconnection — Basic Reference Model: The Basic Model, 1994.
2.
Столлингс В.
Передача данных. 4-е изд. — СПб.: Питер, 2004. С. 123-129.
3.
Поздняков В.А.
Выбор системы команд в рамках универсальной системы обработки потоков данных //
Сборник научных трудов ИТМиВТ. I квартал 2007
года. Москва, 2007.
4.
Поступила в
редакцию 26 декабря