Применение вероятностных моделей для анализа содержания
информационных документов.
Воронин Евгений
Алексеевич,
доктор технических наук, профессор.
Бородин Олег Николаевич,
соискатель, ассистент кафедры Вычислительной техники и
прикладной математики Московского Государственного Агроинженерного Университета
имени В.П. Горячкина.
Условной основной единицей хранения
текстовой информации, находящейся в базе данных, является информационной документ. Под
информационным документом подразумевается набор текстовой информации, сформированной на
естественном языке. Содержание информационного документа представляет собой
связанную общим смыслом последовательность символов алфавита, разделённых между собой
пробелами и другими служебными символами. Под последовательностью символов подразумевается
слово русского языка. Слово – это единица языка, несущая определённую информацию и обладающая
фонетическими и
семантическими свойствами.
В русском языке большое значение имеет
морфологическая изменяемость слова, так как русский язык относиться к языкам
флективного типа. Большинство слов русского языка в тексте представлены в виде
словоформ – слов,
имеющих одну основу,
но обладающих разными флексиями (например, федерация, федерации, федерацией,
федерациям). Для повышения качества поиска по коллекции информационных документов
возникает необходимость
лингвистической обработки содержания информационного документа, включающей выполнение
морфологической обработки словоформ в тексте документа [2].
Текст естественного языка, содержащийся в
информационных документах,
подразделяется на следующие категории:
1. Словоформы – слова, имеющие одну
морфологическую основу,
но различные варианты
написания в результате присоединенных префиксов.
2. Стоп-слова – категория слов, определяющих синтаксические, семантические
связи - к ним относятся союзы, предлоги, местоимения и
т.д.
3. Специальные термины – технические
термины и их сокращённые аббревиатуры, описывающие информационные понятия определённой предметной области.
В результате анализа содержания
информационных документов,
посвященных тематике сельского хозяйства, были выявлены следующее частотные
закономерности содержания
слов русского языка:
·
Доля
«стоп-слов» (не подлежащие индексации предлоги, союзы, наречия) от общего словесного
состава информационного документа составляет
20%.
·
Доля специализированных терминов и определений
составляет 14-17%.
·
Количество текстовых символов, определяющих значения
флективных составляющих словоформы, составляет 3-4 %.
Математический алгоритм лингвистической
обработки текста информационного документа состоит из следующих действий:
1. Запись значения слова в переменную wj.
2. Проверка на принадлежность wj к множеству стоп слов WF.
3. Поиск морфологической основы на базе математической модели
конечного детерминированного автомата:
М = (Q, q0, F, ![]() ,
,![]() ) (1)
) (1)
где:
Q - множество допустимых состояний
автомата, представленных в виде
словоформ русского языка;
F
- конечное множество состояний автомата. Множество F
содержит основы словоформ русского языка.
![]() - входной алфавит, содержащий допустимые входные символы;
- входной алфавит, содержащий допустимые входные символы;
q0 – начальное состояние автомата при
условии, что q0 ![]() Q, q0=wj;
Q, q0=wj;
![]() - функция перехода автомата
- функция перехода автомата ![]()
![]()
![]() → Q.
→ Q.
Последовательность слов в информационном
документе содержит слова, относящиеся к отдельным категориям с определённой
долей вероятности. Символьное значение слова в последовательности можно
представить в виде случайной величины, которая принимает определённые значения
из совокупности, принадлежащей к выявленным категориям.
В результате анализа частотного
распределения слов в
тексте информационного документа существует вероятность перехода межу функциональными блоками алгоритма.
При выполнении алгоритма система в
фиксированный момент времени находится в
определённом состоянии, текущее состояние соответствует
определённому блоку алгоритма, в результате возникает определённое множество
состояний {E1,..,Ee}. Переход из одного состояния в другое осуществляется с вероятностью,
которая определяется особенностями обрабатываемого текста и структурой анализируемого алгоритма. Работу алгоритма лингвистической
обработки текста можно представить в виде последовательности случайных событий,
где так же характерно влияние предшествующих событий на последующие при наличии
начального состояния системы и конечных заключительных состояний. Процессы с такими характеристиками называются
марковскими в честь
русского математика А. А. Маркова [1].
Вероятностная модель, разработанная на
основе принципов построения марковских
цепей и составленная
по алгоритму лингвистической обработки словоформы, представлена на рис. 1.
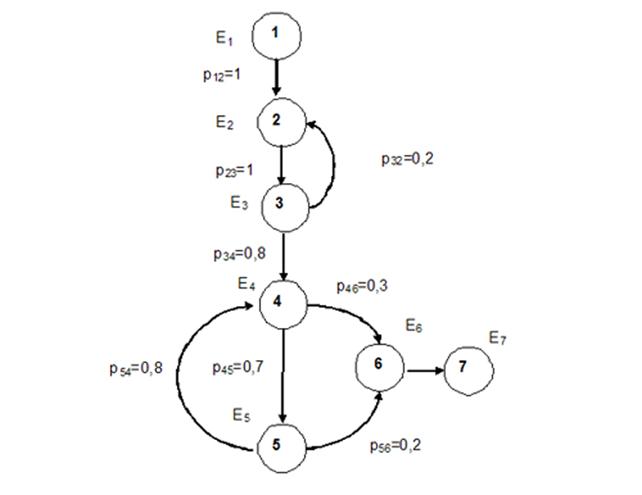
Рис. 1.
Вероятностная модель алгоритма лингвистической обработки
текста информационного документа.
Элемент E1
является первичным элементов цепи в
соответствии с правилами формирования марковских цепей. Первичному элементу не соответствует операции
в алгоритме. Элементом E2 является wj (словоформа),
которая принадлежит к тексту
информационного документа. Существует вероятность p32, что wj может
принадлежать к множеству WF (множество
стоп-слов) в результате проверки в элементе E3. В противном случае wj является словоформой. Элемент E4 реализует функции проверки текущего
состояния q0 = wfk автомата M на
принадлежность конечному множеству состояний. Существует вероятность p46=0,3, что q0 окажется заключительным состоянием
автомата q0 ![]() F, элемент E6 соответствует
конечному множеству состояний автомата. Элемент цепи E5
осуществляет
переход из состояния конечного
автомата
F, элемент E6 соответствует
конечному множеству состояний автомата. Элемент цепи E5
осуществляет
переход из состояния конечного
автомата ![]()
![]()
![]() → Q в состояние q1, которое отличается от q0 отсутствием
последнего символа в обрабатываемой последовательности алфавита. Циклический переход к элементу E4 происходит с вероятностью p54=0,8.
Вероятность перехода p56=0,2 к элементу E6 возникает,
когда обрабатываемая словоформа не была определена среди заключительных
состояний конечного автомата,
состоящих из множества морфологических основ словоформ. В результате автомат принимает исключительное
заключительное состояние qf : ¿
→ «!». Элемент E7 является
заключительным элементом
в цепи и не имеет присвоенных операций.
Основным элементам цепи Маркова, за исключением первого и последнего элемента, соответствует одна
операция.
→ Q в состояние q1, которое отличается от q0 отсутствием
последнего символа в обрабатываемой последовательности алфавита. Циклический переход к элементу E4 происходит с вероятностью p54=0,8.
Вероятность перехода p56=0,2 к элементу E6 возникает,
когда обрабатываемая словоформа не была определена среди заключительных
состояний конечного автомата,
состоящих из множества морфологических основ словоформ. В результате автомат принимает исключительное
заключительное состояние qf : ¿
→ «!». Элемент E7 является
заключительным элементом
в цепи и не имеет присвоенных операций.
Основным элементам цепи Маркова, за исключением первого и последнего элемента, соответствует одна
операция.
Матрица PL
вероятностей перехода между состояниями,
составленная по цепи Маркова имеет вид:
|
PL = |
|
E1 |
E2 |
E3 |
E4 |
E5 |
E6 |
E7 |
|
E1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
|
E2 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
|
|
E3 |
0 |
0,2 |
0 |
0,8 |
0 |
0 |
0 |
|
|
E4 |
0 |
0 |
0 |
0 |
0,7 |
0,3 |
0 |
|
|
E5 |
0 |
0 |
0 |
0,8 |
0 |
0,2 |
0 |
|
|
E6 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
|
E7 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Для построения матрицы коэффициентов и
вектора правых частей в рамках работы
создано программное средство «Анализатор трудоемкости алгоритмов». Оценка
трудоёмкости алгоритма на основе марковской модели позволяет оценить среднюю трудоёмкость алгоритма
[3]. На практике, помимо средней трудоемкости,
возникает
необходимость оценить среднее квадратичное отклонение. Более того, в ряде случаев вес
вершины может представлять случайную величину. Классическая цепь Маркова не
позволяет оценить характеристики разброса входных величин и не позволяет задать в
качестве исходных данных характеристики случайной величины. Поэтому в состав программного средства «Анализатор трудоемкости
алгоритмов» включена имитационная модель анализа трудоёмкости алгоритма.
Результаты анализа трудоёмкости алгоритма лингвистической обработки
содержания информационного документа представлены в таблице 1.
Таблица 1.
Результаты
анализа трудоёмкости алгоритма.
|
Показатель |
Значение |
|
|
цепь
Маркова |
имитационная модель |
|
|
Средние число
операций |
7,36 |
7,68 |
|
Максимальное
число операций |
|
36 |
|
Минимальное
число операций |
|
4 |
|
Среднеквадратичное отклонение |
|
4,26 |
|
Доверительный
интервал |
|
0,37 |
|
Из серии
опытов |
|
|
|
Средние |
|
7,36 |
|
Средние |
|
0,16 |
В результате анализа трудоёмкости алгоритма
лингвистической обработки слов естественного языка, содержащихся в тексте информационного
документа,
сформированы следующие выводы:
- величина среднего числа операций
алгоритма с учётом значения среднеквадратичного отклонения соответствует среднему количеству символов словоформы, относящейся к флексиям;
- минимальное число операций приходится
на значение случайной величины, которое соответствует заключительному состоянию
автомата;
Литература.
1. Баруча-Рид А.Т. Элементы теории марковских процессов и их
приложения / А.Т. Баруча-Рид. – М: Наука,
1969.
2. Леонтьева Н.Н. Автоматическое
понимание текстов: системы, модели, ресурсы / Н.Н. Леонтьева. – Москва
Академия, 2006.
3. Макконелл Дж. А. Основы современных
алгоритмов. 2-е дополненное издание:
Пер. с анг.: М.: Техносфера, 2006.- С. 322-349.
Поступила в
редакцию 14.04.2008 г.