Информационная система визуализации
метазнаний Интернет
Будаев
Денис Сергеевич,
аспирант Самарского государственного
архитектурно-строительного университета.
Научный руководитель – доктор
технических наук, профессор, зав. кафедрой прикладной математики и вычислительной
техники
Пиявский
Семен Авраамович.
В настоящее время в России наблюдается устойчивая тенденция перехода к информационному
обществу[1].
Современному жителю мегаполиса гораздо проще и удобнее найти информацию
(научно-популярная статья, новости) посредством сервисов глобальной сети
Интернет, чем искать, например, ее в местных библиотеках. В данных условиях
развитие эффективных механизмов поиска и обобщения информации является крайне
важной задачей. Существующие поисковые системы позволяют сформировать запрос на
естественном языке и получить набор ссылок на сайты, информационно близкие к
запросу. Однако получить ссылки и получить нужную информацию –разные вещи.
Иногда в поиске необходимых данных пользователям глобальной сети нужно открыть
и посмотреть содержимое не одного десятка сайтов. Таким образом, определенное
количество сайтов представляют собой так называемый «информационный шум». Эти
сайты не имеют отношения к нужной пользователю предметной области и не
представляют интерес для него, а нужная информация, как правило, сосредоточена
на ограниченном множестве сайтов. Чтобы понять это, человеку практически всегда
необходимо ознакомиться с информационным наполнением ресурса, а значит
потратить на это время. Не менее важной задачей является задача представления
пользователю ресурсов Интернет, характеризующих данную предметную области, в
наиболее оптимальном для понимания и работы виде. Человек получает через
зрительный канал до 90% всей информации. При работе с той или иной поисковой
системой мы также воспринимаем полученный перечень гиперссылок через зрительный
канал. Однако существующий и используемый абсолютным большинством поисковых
серверов способ представления результатов запроса в виде простого перечисления
гиперссылок представляется не оптимальным. Более выигрышным видится способ
представления результатов поисковой выборки в виде различных графических объектов,
которые в комплексе способны подключить ранее незадействованные механизмы интуиции,
веками развиваемые эволюцией в человеке.
Изложенная методика, а также реализованная
система позволяют решить указанные проблемы и предлагаются как альтернативная
технология накопления, структуризации,
обобщения и графического представления ресурсов Интернет по различным
предметным областям (рисунок 1).
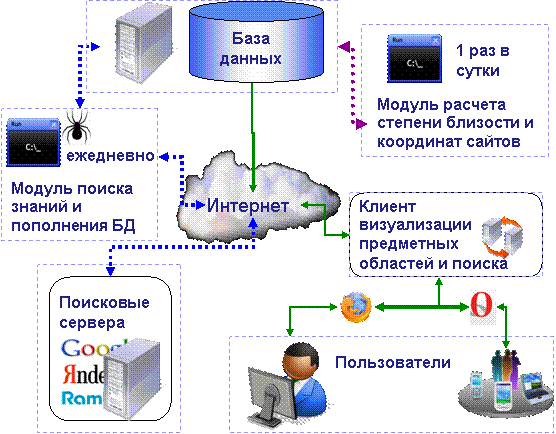
Рис. 1. Схема информационной технологии
структуризации и визуализации ресурсов Интернет в различных предметных областях.
Структура
базы данных в рамках информационной технологии позволяет хранить информационные
запросы, когда-либо участвовавшие в формировании набора сайтов, описывающих
знания Интернет в определенной предметной области[2].
URL-адреса данных сайтов
были получены автоматизировано информационной системой следующим образом:
программно формулировался информационный запрос к определенному поисковому
серверу в виде веб-запроса. В ответ на данный запрос приходил ответ в виде
потока, содержащего код html-страницы,
описывающей полученную поисковую выборку. По содержанию данный html-код ничем не отличается от кода веб-страницы
для веб-браузера, которая содержит
результаты поиска с использованием той же поисковой машины. Данный поток
автоматически обрабатывался, в нем выделялись все URL-адреса в порядке убывания степени близости
(релевантности) к запросу, после чего полученный набор URL-адресов сайтов и запрос, по которому их
получили, заносились в базу данных[3].
В результате
работы программного модуля поиска знаний и пополнения БД была получена первоначально
необходимая информация, описывающая знания Интернет по выбранной предметной области.
Одним из ключевых фактов на данном этапе явилось частичное совпадение наборов URL-адресов сайтов, полученных по разным
поисковым запросам. Отличия наборов заключались еще и в том, что совпадающие
адреса хоть и присутствовали в обеих поисковых выборках, но находились в них на
различных местах (по релевантности к поисковому запросу). Таким образом,
благодаря установленной особенности возможным стало установить степень близости
различных URL-адресов сайтов друг к
другу. Кратко опишем основные этапы работы модуля расчета степени близости и
координат сайтов. Было установлено, сколько раз каждый из сайтов, описывающих
данную предметную область, был получен в результате поисковых запросов. Фактически
данная величина показывает, с каким количеством запросов, характеризующих
предметную область, связан данный URL-адрес,
то есть величина характеризует степень релевантности каждого сайта Интернет к
предметной области, описываемой набором поисковых запросов. Следующей задачей
явилось установление степени близости пар адресов сайтов. Степень близости
каждой пары сайтов определялась по определенному алгоритму. Пусть имеется пара
сайтов, между которыми необходимо установить степень близости. Были определены все запросы, с которыми связан каждый из
сайтов пары, а также места, которые занимает каждый из сайтов пары в поисковой
выборке каждого связанного запроса. Первый сайт пары был получен в результате
трех запросов – «всемирная паутина», «жизнь в цифровом мире», «непрерывное
обучение». Данный адрес расположился в поисковых выборках данных запросов на
12, 83 и 54 местах соответственно. Второй сайт данной пары фигурировал в
результатах 7 поисковых запросов, причем оказалось, что совпадающими у двух
рассматриваемых сайтов являются 2 поисковых запроса. Далее запросы,
присутствующие в поисковых выборках обоих сайтов пары будем называть совпадающими.
Тогда степень близости ![]() между данной парой
адресов определяется следующей формулой:
между данной парой
адресов определяется следующей формулой:
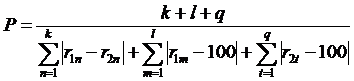 , (1)
, (1)
где ![]() - количество совпадающих запросов данной пары сайтов,
- количество совпадающих запросов данной пары сайтов, ![]() - количество несовпадающих запросов первого сайта пары,
- количество несовпадающих запросов первого сайта пары, ![]() - количество несовпадающих запросов второго сайта пары,
- количество несовпадающих запросов второго сайта пары, ![]() - место первого (
- место первого (![]() - второго) сайта в поисковой выборке совпадающего запроса
- второго) сайта в поисковой выборке совпадающего запроса ![]() ,
, ![]() - место первого (
- место первого (![]() - второго) сайта в поисковой выборке несовпадающего запроса с
номером
- второго) сайта в поисковой выборке несовпадающего запроса с
номером ![]() (с номером
(с номером ![]() ).
).
Вычитаемая
величина 100 в данной формуле показывает, что при отсутствии совпадающего
запроса у одного из сайтов пары в качестве такового принимается запрос, в
котором данный сайт стоит на сотом (последнем) месте. Для примера пары сайтов
на рисунке 3 получаем величину близости
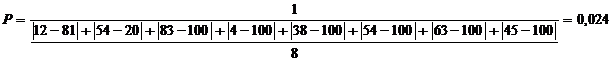 .
.
Чем больше
величина ![]() , тем более схожа данная пара сайтов по информационному
наполнению в рамках поставленных запросов, которые в конечном итоге выделяют
определенную предметную область знаний.
, тем более схожа данная пара сайтов по информационному
наполнению в рамках поставленных запросов, которые в конечном итоге выделяют
определенную предметную область знаний.
Таким
образом, между всеми сайтами, описывающими знания Интернет в определенной
предметной области, установлены количественные отношения. Данные отношения
необходимы для определения оптимальных координат расположения каждого
объекта-сайта в ходе визуализации знаний Интернет в данной предметной области.
Рассмотрим работу алгоритма вычисления оптимальных координат. Для работы алгоритма
необходима матрица расстояний между сайтами. Расстояние между парой сайтов ![]() определяется по
известной величине близости между парой сайтов по следующей формуле:
определяется по
известной величине близости между парой сайтов по следующей формуле:![]()
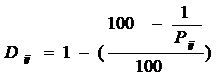 , (2)
, (2)
где ![]() - величина близости для данной пары сайтов (
- величина близости для данной пары сайтов (![]() ,
,![]() ). Для ранее рассмотренного примера и величины близости
). Для ранее рассмотренного примера и величины близости ![]() получим расстояние
получим расстояние 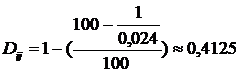 . Чем меньше
данная величина, тем более схожа данная пара сайтов по информационному
наполнению в рамках поставленных запросов. При величине
. Чем меньше
данная величина, тем более схожа данная пара сайтов по информационному
наполнению в рамках поставленных запросов. При величине![]() пара сайтов не имеет областей пересечения в рамках всех
связанных с ними запросов. При величине
пара сайтов не имеет областей пересечения в рамках всех
связанных с ними запросов. При величине![]() имеем пару сайтов с одинаковым информационным наполнением в
рамках всех связанных с парой запросов. Получаем квадратную матрицу расстояний
между сайтами, диагональные элементы которой равны нулю. Упрощенно метод
оптимизации при поиске координат представлена на рисунке 2.
имеем пару сайтов с одинаковым информационным наполнением в
рамках всех связанных с парой запросов. Получаем квадратную матрицу расстояний
между сайтами, диагональные элементы которой равны нулю. Упрощенно метод
оптимизации при поиске координат представлена на рисунке 2.
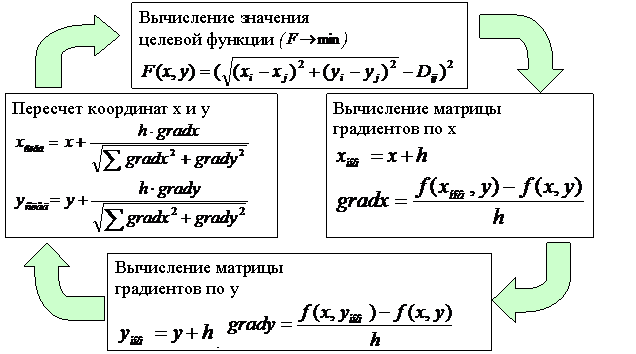
Рис. 2. Упрощенный алгоритм оптимизации
при поиске координат сайтов для визуального представления сайтов Интернет.
Базовым для
реализации оптимизатора был выбран градиентный метод поиска оптимума функции
многих переменных. В дальнейшем созданный на этой основе алгоритм неоднократно
дорабатывался и модернизировался для решения данной конкретной задачи. При
внесении новых объектов в существующую карту визуализации объектов алгоритм не
начинает расчет «с нуля», а пытается интегрировать новые объекты в существующую
схему, постепенно изменяя всю визуальную картину.
При
информационном поиске в рамках описанной методологии пользователь имеет
возможность сформулировать поисковый запрос, как из терминов, так и из
запросов, имеющихся на данный момент в базе данных, выбрав их из списка. Имеется
возможность задать величину глубины
связи поискового запроса пользователя и имеющихся в системе запросов, по
которым будет осуществлен поиск сайтов Интернет, а также отображать или нет
несвязанные с поисковым запросом сайты базы данных. На рисунке 3 изображен результат
работы системы по поисковому запросу «виртуальные сообщества интернет» в рамках
предметной области «Информационное общество». Найдено 9 сайтов с величиной
уровня связи с запросом более 10%.

Рис. 3. Оценка результатов запроса.
Каждый
найденный сайт представлен красной точкой на визуальной карте. При наведении на
точку видно всплывающее меню с информацией, характеризующей сайт. При нажатии
на точку осуществляется переход на соответствующий ресурс глобальной сети.
В настоящий
момент имеется полностью работоспособный прототип системы визуализации метазнаний
Интернет по различным предметным областям, сформирована база данных по сайтам
Интернет, описывающих предметную область «Информационное общество». Запросы для
формирования данной базы были взяты из русско-английского глоссария по
информационному обществу[4].
Основное применение системы – поиск и систематизация предметных знаний,
установление межпредметных отношений, поиск скрытых закономерностей в ходе исследований.
В ходе работы
были решены проблемы проектирования архитектуры системы и структуры базы знаний.
Разработаны механизмы автоматизированного заполнения базы данных с
использованием существующий поисковых серверов Интернет. Созданы необходимые
математические модели и алгоритмы, в частности, модели расчета степеней связи
объектов метазнания и оптимизации координат объектов. Реализованы механизмы визуального
представления знаний и поддержки процесса поиска. Вместе с тем пришло понимание
необходимости наращивания функционала системы, создания дополнительных модулей,
помогающих пользователю информационной системы эффективно оценить полученную
визуальную картину, задействовать механизмы интуиции.
Литература.
1.
Гаврилова
Т.А., Хорошевский В.Ф. Базы знаний интеллектуальных систем. - СПБ: Питер, 2000.
2.
Концепция
формирования информационного общества в России, Одобрена решением Государственной
комиссии по информатизации при Государственном комитете Российской Федерации по
связи и информатизации от 28 мая
3.
Русско-английский
глоссарий по информационному обществу, совместный проект Британского
Совета в России, Института развития информационного общества и проекта «Российский
портал развития», http://www.iis.ru/glossary/.
4.
Симон
Робинсон, Олли Корнес. C# для
профессионалов, том I-II, Издательство «Лори», 2002, 1002 с.
Поступила в редакцию 06.08.2008
г.
[1] Концепция
формирования информационного общества в России, Одобрена решением Государственной
комиссии по информатизации при Государственном комитете Российской Федерации по
связи и информатизации от 28 мая
[2] Гаврилова Т.А., Хорошевский В.Ф. Базы знаний интеллектуальных систем. - СПБ: Питер, 2000.
[3] Симон Робинсон, Олли Корнес. C# для профессионалов, том I-II, Издательство «Лори», 2002, 1002 с.
[4] Русско-английский глоссарий по информационному обществу, совместный проект Британского Совета в России, Института развития информационного общества и проекта "Российский портал развития", http://www.iis.ru/glossary/.