Модели перераспределения ресурсов
Крылов
Александр Изотович
заместитель начальник управления
специальных работ ЗАО «ЭВРИКА», г. Санкт – Петербург,
аспирант Санкт-Петербургского
государственного университета информационных технологий, механики и оптики,
Медведчикова
Мария Георгиевна
инженер управления специальных работ ЗАО
«ЭВРИКА», г. Санкт – Петербург.
Эволюция вычислительных систем проходила по спиральному пути, с точки зрения реализации системы доступа к ресурсам [2].
Первое поколение вычислительных систем строилось на основе однозвенной модели, в которой все вычислительные мощности сосредотачивалась в мэйнфрейме, а клиентская сторона была представлена терминалом, не имеющим собственных вычислительных мощностей, что обуславливалось высокой стоимостью аппаратуры и ее обслуживания.
Расположение всех вычислительных ресурсов, кода и данных в одном центре позволяло сократить стоимость обслуживания клиентских мест и приложений. Кроме того, вычислительные мощности центрального узла оптимально распределялись по времени, обеспечивая выравнивание нагрузки на сервер.
Эта модель оставалась
эффективной в течение долгих лет, за которые было создано множество решений, и
ее закат наступил в силу экономических, а не технологических причин. Массовое
распространение дешевых персональных компьютеров сделало экономически
целесообразным перенос части вычислительных задач с сервера на клиентский
терминал, в качестве которого выступал персональный компьютер. Это послужило
толчком для создания двухзвенной модели,
которая доминировала два десятилетия. Архитектура «клиент-сервер» позволила
снизить нагрузку на сеть, связанную с передачей данных, и увеличить скорость их
обработки (локальные вычисления и хранение данных на клиенте было эффективнее
использования дорогих и к тому же медленных сетей того периода).
Кризис двухзвенной модели
также обусловили экономические факторы, а его основой стало изменение стоимости
передачи данных по сети. Целесообразно снизить нагрузку на терминал
(персональный компьютер) и снова перенести ее на сервер. Взрывной рост «Internet»,
появление множества удаленных приложений с Web-интерфейсом и снижение стоимости
передачи данных привели к разделению вычислительной мощности на серверной
стороне и созданию сначала трехуровневой,
а затем и распределенной модели вычислений.
Трехзвенная модель предполагает разделение функций между сервером базы данных и
сервером приложений. При этом происходит разделение данных и процедур по разным
серверам, каждый из которых выполняет наиболее подходящую для него работу. Вариацией
такой архитектуры является многозвенная модель, в которой может использоваться
более чем один сервер СУБД или сервер приложений.
Развитие технологий «grid» для вычислительных задач. Одним из основных потребителей вычислительных мощностей
при выполнении расчетов является научное сообщество, причем запросы на эти мощности
серьезно превышают возможности финансирования таких проектов. Был выбран путь
параллельного исполнения сложных задач на множестве связанных небольших дешевых
компьютеров.
«Grid» для бизнеса в значительной степени имеет
экономическое происхождение. За время существования
ИТ-индустрии в нее были вложены огромные средства, и после кризиса западной
экономики в 2000-2003 годах многие руководители предприятий задумались об
эффективности таких вложений. Вопрос заключался не в том, чтобы просто урезать
расходы, а в том, чтобы максимально эффективно использовать инвестиции. При
этом владельцы бизнеса и руководители готовы инвестировать дополнительные
средства для создания нового поколения эффективных ИТ-систем, не страдающих
недостатками систем предыдущих поколений.
Так или иначе, платить
только за оказанные ИТ-услуги и свободно манипулировать ИТ-ресурсами захотели
многие. После периода поиска за этой идеей закрепилось название «grid», ранее
имевшее хождение только в научных кругах.
«grid» для бизнеса —
это идеология, включающая в себя набор технологий, программных и аппаратных
решений, бизнес-процессов и организационных изменений. Ее основой является
распараллеливание вычислительных мощностей на множестве недорогих серверов,
связанных в единую сеть. Ключевым свойством такой системы, кроме распараллеливания
вычислений, является динамическое перераспределение вычислительных ресурсов «по
требованию» между разными задачами. С точки зрения бизнеса эта модель реализует
парадигму utility computing, которая предполагает предоставление услуг
бизнес-подразделениям и оплату использованных вычислительных мощностей «по
факту».
Основным критерием для
перенесения задач в среду «grid» является возможность их распараллеливания. По
своей природе бизнес-приложения сильно отличаются от вычислительных задач.
Реализованные на сегодняшний день трехзвенная и распределенная модели
вычислений в наибольшей степени соответствуют идее «grid», но распараллеливание
в них происходит только на уровне серверов приложений и Web-серверов.
При этом такие системы
масштабируются до гораздо более высокого уровня производительности. Например, в
таблице результатов самого распространенного теста на производительность SAP SD
(Sales and Distribution) рекордное быстродействие в трехзвенной архитектуре
достигается в конфигурации, состоящей из одного 64-процессорного сервера «HP
Integrity» для СУБД и 160 четырехпроцессорных «HP Integrity rx4640» для
серверов приложений. В двухуровневой архитектуре результаты в пять раз
скромнее, а достигаются они на 64-процессорном сервере архитектуры Power5.
Как бы то ни было, в том и
другом случае уровень СУБД реализуется в SMP-архитектуре, а не на параллельных
(кластерных) системах. Таким образом, несмотря на возможность распараллеливания
вычислительных ресурсов бизнес-приложений, остается еще одна часть, которую
пока очень трудно уложить в структуру «grid» для бизнеса, — СУБД.
Существует несколько
моделей, которые учитывают особенности поведения СУБД в «grid»-средах, например
технологии «Oracle», позволяющие создавать кластеры в архитектуре «Shared Disk».
Основная проблема таких кластеров заключается в том, что они идеально работают
только при идеальном распределении запросов между узлами кластера.
На деле возможна ситуация,
в которой данные, измененные на узле А, еще находятся в оперативной памяти
этого сервера и не сброшены на общий диск. Если запрос к этим данным поступил
на узел В, то через сетевой интерфейс запрашивается узел А, который сбрасывает
данные на общий диск, откуда В может их считать. В результате вместо одной
медленной операции чтения с диска выполняется две такие операции.
Технология, известная как «Cache
Fusion», была предложена еще в «Oracle8» и стала основой «OracleRAC» в «Oracle9».
Суть ее состоит в том, что необходимые данные передаются на другой узел по
быстрому сетевому соединению. В результате общая производительность системы
даже возрастает (по некоторым оценкам, до 40%), поскольку полностью исключаются
все медленные операции с дисками. При этом данные уже как бы находятся в кэше А
и могут быть быстро переданы В. Начиная с «Oracle9», управление таким процессом
передается специальному сервису «Global Cache Service», обслуживающему все узлы
и разрешающему конфликты. Фактически с небольшими добавлениями, «Cache Fusion»
стал основой «Oracle10g».
В отличие от систем «SMP» и
«ccNUMA» (в них реализуется общий доступ к памяти всех процессоров и задач) или
кластерных систем (каждый узел имеет собственный массив памяти), в «Oracle»
была реализована смешанная архитектура: кэши являются общими для всех узлов, а
все остальные задачи оперируют индивидуальными массивами памяти на узлах.
Теоретически такая система способна решить основное противоречие между
вертикальным и горизонтальным масштабированием: производительность растет за
счет увеличения числа процессоров в рамках одного сервера и числа небольших
серверов в кластерной конфигурации.
Проблемой этой технологии
стало «несовершенство нашего мира»: аппаратные решения практически всегда менее
эффективны, чем их программная эмуляция. Фактически «Oracle10g» программным образом
эмулирует работу коммутатора между процессорными блоками в архитектуре «ccNUMA».
Как известно, такой коммутатор является одной из наиболее дорогих и сложных
частей SMP-компьютеров, и не случайно секретом его создания владеют меньше десятка
компаний, включая HP, IBM, Sun Microsystems, Fujitsu и SGI.
Казалось бы, устранение
необходимости в таком коммутаторе, замена его простым соединением узлов
кластера и перенос части функций на программный уровень могут привести к
существенному упрощению и удешевлению масштабирования систем при увеличении
надежности. В реальной жизни оказалось, что сложность коммутатора обусловлена
тем, что простые системы просто неэффективны для решения столь сложных задач.
В «Oracle Grid» неизбежно
возникают конфликты согласований кэшей и перегрузка соединения, причем эти
трудности увеличиваются с ростом числа узлов. Если исходить из архитектуры
сегодняшних SMP-систем, имеющих 128 процессоров, то это соответствует
32-узловой конфигурации кластера. Возможна ли такая масштабируемость? Пока однозначного
ответа нет.
Еще одно
программно-аппаратное решение в области «grid»
предлагает «Fujitsu Siemens Computers». Ее технология «FlexFrame» позволяет динамически обслуживать
«SAP Business Suite» на серверах-«лезвиях». В рамках этой технологии можно
запускать дополнительные серверы, устанавливать и запускать на них приложения «SAP»,
проводить мониторинг и восстановление после сбоев. Однако и «FlexFrame» еще
далеко до «grid» для бизнеса, так как она позволяет перераспределять ресурсы
только в рамках одного приложения и не обеспечивает достижения уровня «utility computing». Впрочем, в «Fujitsu Siemens Computers» и не настаивают
на этом, используя для обозначения своей инициативы слова «Autonomic Computing».
В большой политике вокруг «grid»
участвуют крупнейшие производители компьютеров, но вполне очевидно, что полное
решение пока не может предложить ни одна из компаний. При отсутствии полного
решения основные компании создают промежуточные решения, фокусируясь на
построении адаптивной информационной инфраструктуры предприятия. Но поскольку
автоматическая балансировка нагрузки и перераспределение вычислительных
мощностей еще труднореализуемы, упор делается на возможность быстро и легко
перестраивать инфраструктуру вручную.
Движение в этом направлении
начала компания «Hewlett-Packard». Последние анонсы IBM показывают, что в
фокусе «grid»-стратегии этой компании сейчас находится идея адаптивности.
Подходы Sun идеологически ближе к предложениям «Fujitsu Siemens», с поправкой
на последовательное применение архитектуры J2EE.
Пожалуй, наиболее интересной
компанией является SAP. Среди разработчиков этой компании нашлись люди,
понимающие, что после разрешения всех сегодняшних технических сложностей в мире
«grid» возникнет проблема взаимодействия решений на всех уровнях. Предположим,
все проблемы решены и у вас в «grid»-среде есть два сервера от разных
производителей. Будут ли они совместно балансировать нагрузку? Скорее всего,
даже на аппаратном уровне эти системы окажутся несовместимыми.
Еще проблематичнее
взаимодействие, если принять в расчет программное обеспечение. Допустим,
имеются два сервера; на одном работает «Oracle E-Business Suite», а на другом —
«Siebel CRM». На сегодняшнем уровне развития их совместная работа с передачей
вычислительных ресурсов нереализуема.
Именно поэтому вопрос
стандартов стоит так остро. Существует комитет по языку «Data Center Markup
Language», недавно вошедший в «OASIS». Имеется «Enterprise Grid Alliance»,
объединяющий ряд компаний ИТ-рынка. Однако, одна из компаний сумела сделать
предложение, которое выделяется даже на уровне разработок этих авторитетных организаций.
В концепции «SAP NetWeaver»
современные ИТ-системы воспринимаются не просто как набор различных систем и приложений,
а как многоуровневая среда, аналогичная стеку стандартов TCP/IP. В ее рамках
рассматривается построение модели как бизнес-процессов, так и компьютерных
процессов, управление знаниями, бизнес-функциями и многое другое, за
исключением уровня физической реализации аппаратной части и операционной
системы. Именно такая модель может стать основой интегрированных «grid2»-сред
для бизнеса. К сожалению, это предложение последовало слишком рано: пока не
только партнеры, но и часть сотрудников самой SAP видят в «NetWeaver» не
платформу для «grid»-решений, а лишь очередной набор интерфейсов для связи с
другими системами.
Несмотря на трудности
технической реализации и координации усилий игроков, у grid-решений для бизнеса
есть важное свойство, которое делает их пришествие неизбежным. Это экономически
более эффективная модель, чем предыдущие идеи, которые можно свести к построению
инфраструктуры ИТ за счет «повторного» использования вычислительных ресурсов
при изменении бизнес - запросов и упрощения системы администрирования.
Уже ясны основные
характеристики реальной «grid»-архитектуры и требования к ней:
·
«grid» — это методология
и технология, объединяющая большую часть современной компьютерной
инфраструктуры (серверы, хранилища данных, приложения, системы управления и
т.п.);
·
с точки зрения
технологий «grid» не является ни готовым продуктом (или набором продуктов), ни
компонентом какого-либо продукта или сервиса, но способом организации
инфраструктуры, основанным на распределенной архитектуре и динамическом
распределении нагрузки всего набора приложений;
·
с точки зрения
потребителя, «grid» — это сервис, обеспечивающий необходимые вычислительные
ресурсы «по требованию» («grid»-система не нуждается в регулярной перенастройке
при изменении списка задач или уровня нагрузки в каждой задаче. При этом
сложность решения скрыта от потребителя, и он оплачивает только оказанные ему
услуги, а не стоимость инфраструктуры).
«grid» строится на основе уже существующих технологий. Мир «grid»
будет состоять из набора сервисов, зарегистрированных в депозитарии, который
должен описывать систему, где каждый сервис доступен, разделяем, управляем, где
за пользование каждым ресурсом может быть выставлен счет потребителю.
Гетерогенная природа современных информационных систем требует, чтобы технологии «grid» были полностью основаны на индустриальных стандартах, обеспечивающих работу компонентов любого производителя. Эти сервисы будут в достаточной степени защищенными, отказоустойчивыми и быстродействующими. Возможно, завтрашний день внесет свои коррективы, но в том, что именно на таких принципах станут строиться будущие информационные системы, можно быть уверенным [2].
Компания «Hewlett-Packard» в течение нескольких лет продвигала возможности «utility computing» в своем программно-аппаратном комплексе «Utility Data Center». Осенью 2004 года было решено отказаться от дальнейшего развития «UDC», оказавшегося чересчур тяжелым, сложным, дорогим и закрытым. Однако это вовсе не означало отказа от идей «utility computing»: они составляют основу стратегии HP в области продуктов корпоративного уровня и стратегии создания адаптивного предприятия. В декабре 2004 года в семействе программных продуктов «HP OpenView», предназначенных для управления ИТ-инфраструктурой, появилась система «Automation Manager». Она переносит присущие «UDC» возможности динамического перераспределения ресурсов центров данных в интересах бизнес-приложений в открытую модульную среду, способную объединять аппаратные платформы и управляющие приложения разных производителей [1].
Система «Automation Manager» объединяет в себе технологии
компаний «Novadigm» и «Consera», а также последние собственные разработки «HP
Labs». Три «кита» автоматизации динамического перераспределения ресурсов центра
данных в ответ на требования бизнеса таковы: управление конфигурациями и изменениями
ИТ-инфраструктуры (Novadigm), моделирование и адаптация ИТ-сервисов под нужды
бизнеса в динамике (Consera), анализ доступных ИТ-ресурсов и реализация
изменений в конфигурации ИТ (HP Labs).
Управление конфигурациями и изменениями ИТ-среды —
центральный процесс ИТ-службы в модели «ITSM» (IT Service Management). Он
обеспечивает предоставление ресурсов инфраструктуры (серверы, системы хранения,
пропускная способность сети, приложения) для реализации определенного
ИТ-сервиса (например, для обработки финансовых транзакций или корпоративной
системы электронной почты). Пакет «Radia» компании «Novadigm», функции которого
использует «Automation Manager», автоматизирует установку программного
обеспечения на разные аппаратные и операционные платформы и следит за поддержанием
нужных конфигураций ИТ-инфраструктуры. Отличительной чертой управления конфигурациями
и изменениями в «Radia» является автоматизация этих операций на базе модели
«желаемого состояния» (desired-state automation), а не с помощью скриптов,
описывающих возможные ситуации в ИТ-инфраструктуре.
Система позволяет задать политики конфигурирования
пользовательских рабочих мест или серверов организации и автоматически
отслеживает соответствие текущей конфигурации заданной политике. Например,
«желаемое состояние» ИТ-инфраструктуры может определять следующее: на каждом ПК
в отделе продаж должна быть установлена последняя версия почтового клиента «Microsoft
Outlook», а каждый «Unix»-сервер должен иметь свежую программную «заплату».
Система будет автоматически контролировать выполнение этих условий и при
необходимости настраивать конфигурацию систем.
Однако автоматической поддержки нужной конфигурации
ИТ-инфраструктуры еще недостаточно для динамического реагирования на требования
бизнес-приложений. Необходима возможность изменения описаний «желаемого
состояния», в соответствии с которыми будет настраиваться система управления
конфигурациями. «Automation Manager» задействует средства мониторинга и анализа
производительности бизнес-приложений (чтобы выявлять новые требования), а также
средства моделирования и автоматической настройки ИТ-сервисов (чтобы задавать
изменение параметров конфигурации). Еще одна задача «Automation Manager» —
оптимизация загрузки ресурсов центра данных. Анализ параметров использования
серверных мощностей и систем хранения в режиме реального времени, их сравнение
с заданными шаблонами загрузки в совокупности с применением инструментов
перераспределения ресурсов позволяют избежать простоев и перегрузок аппаратных
систем.
«Automation Manager» работает с моделями трех типов —
бизнес-процесса, ИТ-сервисов и «желаемого состояния» ИТ-конфигураций. Переходя
от модели к модели, от уровня к уровню, система детализирует информацию об
изменении требований бизнес-приложения, трансформируя ее в реальные действия по
изменению конфигурации ИТ-ресурсов, поддерживающих это бизнес-приложение (см.
рис.1).
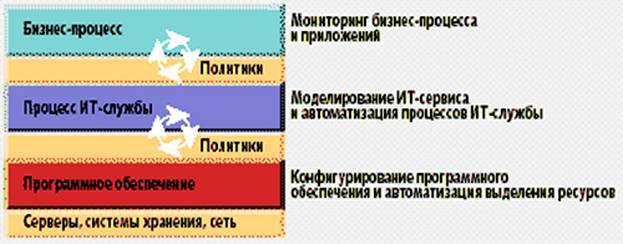
Рис.
1.
«HP OpenView Automation Manager» — три уровня функциональности.
Основные возможности «Automation Manage» таковы:
·
анализ результатов
мониторинга производительности бизнес-приложений, моделирование соответствующих
ИТ-сервисов и предсказание будущих требований;
·
динамическое
предоставление ИТ-ресурсов в неоднородной среде центра данных;
·
непрерывный контроль
над соответствием конфигурации ИТ-инфраструктуры заданным политикам.
Для динамического перераспределения ИТ-ресурсов «Automation
Manager» обращается к системе управления изменениями и конфигурациями, а также
к инструментарию управления ресурсами, такому как система управления серверами
HP «System Insight Manager».
Динамическое реагирование ИТ-инфраструктуры на изменение
производительности бизнес-процессов во многом основано на разработках исследователей
«HP Labs». Здесь, в частности, были созданы средства анализа ИТ-ресурсов,
доступных для поддержки новых бизнес-требований. Эти средства учитывают текущую
загрузку и другие ограничения центра данных и нацелены на создание системных
конфигураций, позволяющих такие требования удовлетворить. Исследователи
подчеркивают сложность своей работы: «Такой программный инструментарий должен
определять не только доступную емкость (число процессоров и объемы памяти) и
особенности поведения сложных аппаратных систем, но и возможности разных
операционных систем. Кроме того, он должен предотвращать конфликты между ними.
И все это — при условии соблюдения множества ограничений, обеспечивающих
нормальную работу ключевых систем центра данных». Для решения указанных проблем
разработаны технологии, которые реализуют три основные функции.
Компоновка ресурсов на базе политик. Пользователи получают возможность формирования моделей
компоновки систем центра данных на базе заданных правил и лучших практик. Это
позволяет автоматизировать создание конфигураций, соответствующих заданным
политикам.
Управление мощностями центра данных. Используются алгоритмы планирования и управления объемами
ресурсов, позволяющие отслеживать сложные требования к ресурсам и реагировать
на них.
Назначение ресурсов.
Применяются математические методы, гарантирующие, что новые приложения получат
требуемые ресурсы (например, пропускную способность сети) и что добавление этих
приложений к разделяемому пулу ресурсов не создаст «узких мест».
«Automation Manager» поддерживает динамическое выделение на
базе заданных политик полного программного стека сервера, включая операционную
систему, «заплаты», приложения, контент в различных форматах и системные
параметры. Кроме того, существуют средства выделения мощностей серверов-лезвий
на основе специальных критериев (типа информации о шасси и слотах сервера). «Automation
Manager» поддерживает возможность параллельного развертывания образа одной и
той же операционной системы на множестве устройств, а также специальные
шаблоны, служащие для ускорения и упрощения установки и конфигурации ряда
популярных программных систем (Web-сервер «Apache», серверы приложений «BEA
WebLogic и «IBM WebSphere», серверы баз данных «Microsoft SQL Server» и «Oracle»,
системы «Microsoft Internet Information Server и Exchange Server» и др.). Все
операции по перераспределению мощностей центра данных могут выполняться в
динамическом режиме, вручную системным администратором или автоматически в
соответствии с заданным расписанием.
Возможности «Automation Manager» можно проиллюстрировать на
примере деятельности финансовой фирмы. В определенный момент (скажем, во второй
половине дня в пятницу) на ней происходит всплеск активности операций по
вкладам, вызывающий серьезные перегрузки в ИТ-инфраструктуре. Получив сигнал о
замедлении выполнения операций, система проанализирует поддерживающие этот
процесс ИТ-ресурсы, существующие соглашения об уровне обслуживания, а также,
возможно, некоторые «исторические» данные о производительности приложения. На
основании этой информации будет выделен дополнительный сервер, который примет
на себя часть нагрузки от приложения обработки финансовых транзакций. Когда
напряженность ситуации снизится, «Automation Manager» переконфигурирует
инфраструктуру.
«Automation Manager» предоставляет и целый ряд
возможностей, связанных с поддержанием конфигурации ИТ-инфраструктуры в
соответствии с заданными политиками. Они реализуются также путем интеграции с
инструментарием управления изменениями и конфигурациями. К ним относятся
средства управления операционными системами, «заплатами», приложениями на
серверах и конфигурационными параметрами. Использование централизованной базы
данных конфигурационного управления, в которой собирается вся информация о
разнородных ресурсах центра данных и их конфигурациях, является необходимым
условием для получения единого представления об ИТ-операциях, для управления
загрузкой и динамического выделения ресурсов под нужды приложений.
«Automation Manager» — открытая модульная система, базирующаяся на принципах сервис-ориентированной архитектуры. Это означает, что HP отказывается от замкнутости Utility Data Center и пытается реализовать возможности «utlity computing» в неоднородной среде. Действительно, «Automation Manager» опирается в своей работе на внешние инструменты управления ИТ-инфраструктурой, прежде всего — на механизмы мониторинга производительности бизнеса, управления конфигурациями и системами центра данных. По заявлениям HP, продукт может интегрироваться не только с модулями семейства «OpenView», но и с решениями других поставщиков и позволяет клиентам пользоваться уже имеющимися у них системами. Это реальный инструмент динамического выделения и перераспределения в интересах бизнеса консолидированного пула ресурсов центра данных [1, 3].
Развитие технологий перераспределения ресурсов, вопрос которого особенно остро стоит в связи с развитием и усложнением коммерческих вычислительных систем, идет по пути реализации концепции «grid», основанной на идее «utility computing». При этом не следует забывать о безопасности перераспределяемых ресурсов, особенно информационных ресурсов. В связи с этим необходимо серьезно подойти в вопросу использования системы обнаружения атак.
Литература.
1. Дубова Н. Менеджер автоматизации вместо коммунального центра данных // Открытые системы – 2005. - № 05-06.
2. Елашкин М. Четыре источника «grid» для бизнеса // Открытые системы – 2004. - № 12.
3.
Центры обработки и хранения данных // - 2006. - www.topsbi.ru.
Поступила в редакцию 10.10.2008 г.