Проблемы
автоматизированного исследования качества программного кода
Звездин
Сергей Владимирович,
аспирант, ассистент кафедры
информатики Южно-Уральского государственного университета.
Введение
Качество создаваемого программного обеспечения
является ключевым вопросом в современной дисциплине программной инженерии. Для
обеспечения высокой степени качества программного кода в индустрии содержится
ряд методов и практик, внедряемых в процесс разработки программного обеспечения.
Задача управления качеством программного обеспечения разделяется на две
составляющие – мониторинг и управление. Эта задача является достаточно сложной,
чтобы полностью ее автоматизировать. Однако она поддается частичной
автоматизации. Для этого необходимо решить три подзадачи:
1)
построить модель определения качества программных компонент;
2)
построить модель определения проблемных мест в программном
коде и формирования рекомендаций по улучшению;
3)
построить модель для классификации изменений в программном коде.
Первая и третья задачи решают вопросы мониторинга
качества программного обеспечения. При этом первая задача позволяет
автоматизировать процесс получения информации о качестве программных компонент
полностью в автоматическом режиме, а третья – решает вопрос о типе изменения в
программном коде для построения более эффективного процесса ручного анализа
кода.
Вторая задача позволяет выявить возможные проблемные
компоненты программной системы, на которые следует обратить внимание. Для
решения этой задачи используется информация, полученная при решении первой
задачи.
Определение качества
программных компонент
Качественные характеристики носят субъективный
характер и для различных ситуаций определяются различными способами. Характеристики
программного кода определяются на основе метрик – численных показателях,
вычисляемых на основе программного кода. Однако зачастую разработчики программного
обеспечения не в состоянии адекватно оценить значение той или иной метрики,
поскольку не до конца понимают её природу. Поэтому для упрощения понимания
состояния проекта на основе характеристик кода предлагается использовать обобщенный
набор критериев качества:
1)
сложность программных компонент;
2)
связность программных компонент;
3)
структурированность программных компонент;
4)
документированность программного кода;
5)
подверженность ошибкам.
Каждая из приведенных характеристик программного
кода не имеет четкого численного выражения, а вычисляется как комплексный
критерий на основе набора числовых характеристик. Поэтому результат вычисления
характеристики представляется лингвистически. Таким образом, задачу определения
качественных характеристик программного обеспечения можно отнести к задаче
классификации состояния программного проекта к одному из классов, отражающих
качественные характеристики проекта. Поскольку критерии качества представлены в
виде лингвистических переменных, то для формализованного представления
предлагается использовать математический аппарат нечеткой логики (fuzzy logic)
[1].
При использовании аппарата нечеткой логики четкие
значения входных характеристик (метрик) следует преобразовать в нечеткие
значения (процедура фуззификации). После этого следует воспользоваться
правилами нечеткого вывода для получения решения. Поскольку модель должна
формировать четкие решения, на выходе необходимо производить перевод полученных
нечетких переменных в четкие значения (процедура дефуззификации). Процесс
нечеткого вывода можно представить в виде схемы, представленной на рис. 1.
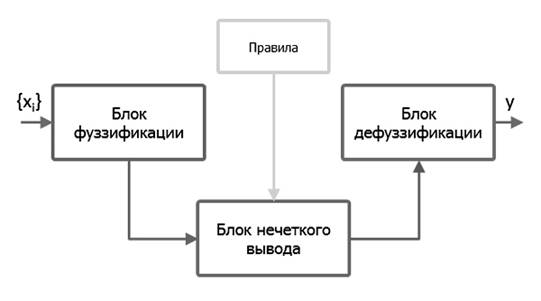
Рис. 1.
Модуль нечеткого вывода.
Процесс нечеткого вывода основывается на блоке
нечеткого вывода. В этом блоке производится агрегирование степеней истинности и
принятие решения. Блок нечеткого вывода основывается на базе правил, которая
также называется лингвистической моделью.
Для реализации поставленной задачи классификации
программной системы предлагается построить структуру нечеткой продукционной
нейронной сети на основе структуры Ванга-Менделя. Нечеткая нейронная
продукционная сеть Ванга-Менделя строится на основе нечеткой продукционной
модели, основанной на правилах типа MISO:
Пi: IF x1
это Ai1 AND … AND xj это Aij THEN y это Bi, где i = 1, ... , n.
В приведенной выше структуре правил множество xi
– это множество четких входных переменных, Aij – это нечеткие
значения принадлежности переменной к одному из классов, а у – это значение выходного сигнала, выраженного нечетким значением.
Для заданной структуры нейронной сети алгоритм нечеткого вывода базируется на
следующих принципах:
·
входные переменные являются четкими;
·
функции принадлежности всех нечетких множеств представляются
функцией Гаусса;
·
аккумулирование активизированных заключений правил не производится;
·
метод дефуззификации – средний центр.
Опуская промежуточные преобразования можно
установить, что значение выхода нейронной сети будет иметь результат,
описываемый выражением:
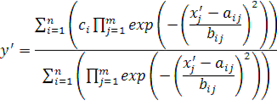
где aij
и bij – параметры функций
принадлежности нечетких множеств предпосылок правил; ci – параметр функции принадлежности нечетких
множеств заключений правил.
Структура нейронной сети (рис. 2) состоит из четырех
слоев – входного и выходного слоя, выполняющий фуззификацию и дефуззификацию
переменных, а также двух скрытых слоев, реализующих алгоритм нечеткого вывода.
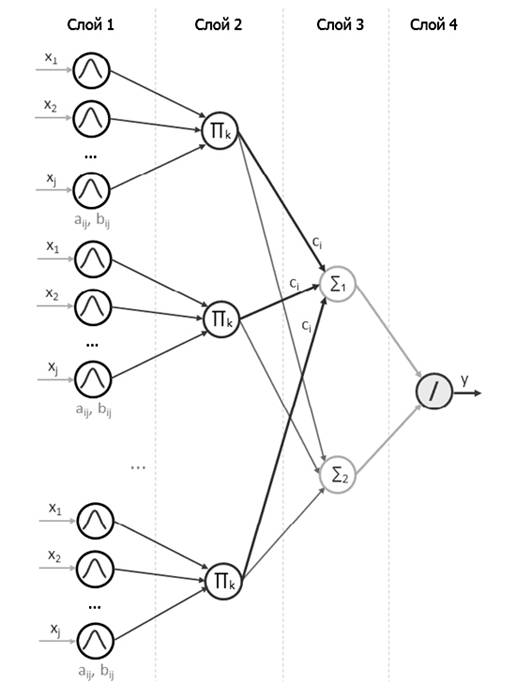
Рис. 2.
Структура нечеткой нейронной продукционной сети.
Слой 1 выполняет фуззификацию
входных переменных {xj}.
Элементы этого слоя вычисляют значения функций принадлежности ![]() , заданных функциями Гаусса с параметрами aij и bij.
Слой 2 осуществляет агрегирование
степеней истинности предпосылок соответствующих правил. Фактически, элементы
этого слоя вычисляют произведение значений, поступающих на вход этого слоя. Слой 3 содержит два нейрона – третьего
и четвертого типа. Первый элемент служит для активизации заключений правил в
соответствии со значениями агрегированных в предыдущем слое степеней истинности
предпосылок правил. Второй элемент слоя проводит
вспомогательные вычисления для последующей дефуззификации результата. Слой 4 состоит из единственного нейрона
пятого типа и выполняет дефуззификацию выходной переменной.
, заданных функциями Гаусса с параметрами aij и bij.
Слой 2 осуществляет агрегирование
степеней истинности предпосылок соответствующих правил. Фактически, элементы
этого слоя вычисляют произведение значений, поступающих на вход этого слоя. Слой 3 содержит два нейрона – третьего
и четвертого типа. Первый элемент служит для активизации заключений правил в
соответствии со значениями агрегированных в предыдущем слое степеней истинности
предпосылок правил. Второй элемент слоя проводит
вспомогательные вычисления для последующей дефуззификации результата. Слой 4 состоит из единственного нейрона
пятого типа и выполняет дефуззификацию выходной переменной.
Таким образом, полученную нейронную структуру можно
использовать в качестве модели, которая на вход принимает метрические значения,
а на выходе генерирует степень принадлежности к одному из термов
лингвистической переменной.
Метод определения проблемных
участков программного кода
После вычисления характеристик качества эту
информацию можно использовать для определения проблемных участков программного
кода. Для этого производят агрегирование характеристик качества и вычисляют
некоторую заранее определенную функцию. Эта модель называется стратегиями обнаружения. Стратегии
обнаружения – это модель, которая позволяет сформировать рекомендации по
улучшению качества, основываясь на показаниях характеристик качества проекта.
Стратегия обнаружения представляет собой некоторый алгоритм, заданный каскадом
логических условий (рис. 3).
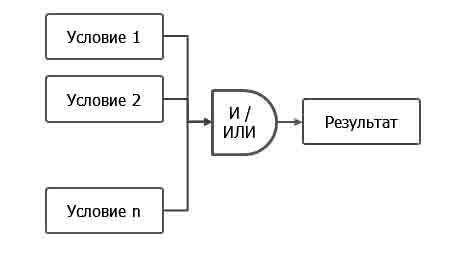
Рис. 3.
Схематическое представление стратегии обнаружения.
Каждое условие представляет собой сравнение одной из
характеристик с эталонным значением. В качестве значений используются
агрегированные значения характеристик проекта (метрик).
Как видно, результат представлен в виде логического
значения, который говорит о том, сработала или нет данная стратегия обнаружения
(ИСТИНА/ЛОЖЬ). Если стратегия обнаружения сработала, то считается, что
анализируемая часть проекта подвержена дефекту, описанному данной стратегией
обнаружения. В этом случае можно давать рекомендации по улучшению качества.
В своих работах по исследованию кода М. Фаулер
вводит понятие «запаха кода» [2]. Этот термин обозначает проблемный участок программного
кода. Автор приводит наиболее типичные ситуации, а также указывает типы
рефакторинга (улучшения структуры) программного кода. Таким образом, каждый «запах
кода» может быть представлен в виде одной или нескольких стратегий обнаружения.
Для построения списка рекомендаций по улучшению
качества программного кода, после вычисления характеристик кода, производится
расчет всех доступных стратегий обнаружения для каждого элемента программного
кода. Те стратегии обнаружения, которые вернут значение «ИСТИНА» заносятся в
список для последующего отображения. Общий алгоритм работы стратегий
обнаружения для программного кода приведен на рис. 4.
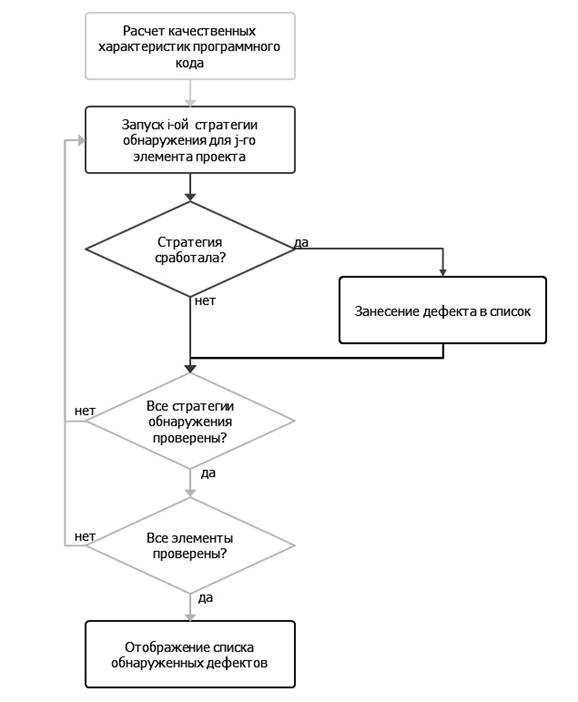
Рис. 4.
Алгоритм работы стратегий обнаружения для программного кода.
Конечный список стратегий обнаружения подбирается
индивидуально для конкретных типов проектов и инструментальных средств
разработки.
Классификация изменений
программного кода
Одна из наиболее эффективных практик обеспечения
качества программного кода – ручной просмотр программного кода. Эта
практика подразумевает обязательный просмотр программного кода другим
участником команды с целью выявления возможных недостатков. В ходе этой
процедуры другой участник команды может обнаружить дефекты, которые другой
разработчик пропустил. Зачастую просмотр кода осуществляется архитектором или
более старшим разработчиком.
Однако, несмотря на эффективность процесса просмотра
программного кода, он требует времени на его проведение. На критических этапах
проекта у участников команды часто не хватает времени на проведение операции
просмотра, и ею пренебрегают. В то же время, не все изменения следует
просматривать другим участникам – в процессе работы производится множество
незначительных изменений, просмотр которых – пустая трата времени. Поэтому для
увеличения эффективности работы команды разработчиков предлагается ввести
классификацию изменений программного кода. Классификация позволит определить
тип изменения и не выполнять просмотр незначительных изменений программного
кода.
Для определения метода классификации изменений
программного кода, представим некоторую программную систему, которая
подвергается изменениям с течением времени. Текущее состояние программного кода
обозначим как Mt. Тогда изменение программного кода с течением
времени можно представить как изменение δt.
Каждое изменение δt можно отнести к
одному из классов. Каждый класс характеризуется целью изменения. Оценить
изменение δt можно путем вычисления набора метрик изменений для
него. Тогда для автоматизации процесса классификации изменений можно
воспользоваться методом кластеризации метрик изменения [3, 4]. Это даст
возможность объединить изменения по группам и, таким образом, определить схожие
изменения.
Однако недостатком метода кластеризации метрик
является невозможность отнесения изменения к какому-либо конкретному классу –
вместо этого методы кластеризации просто выделяют объекты в группы (указывая
тем самым степень их «похожести» друг на друга). Эту проблему можно решить путем
использования нечеткой продукционной нейронной сети [1], описанной ранее.
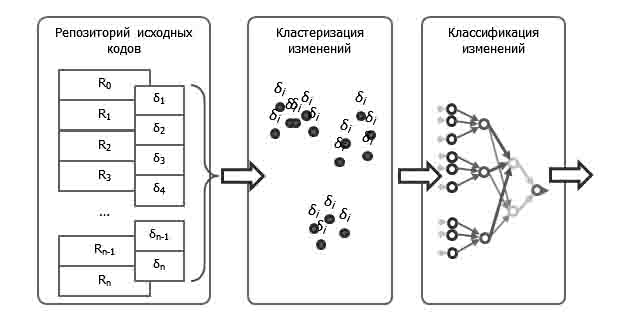
Рис. 5.
Модель классификации изменений программного кода.
Для классификации изменений программного кода
необходимо понять характер этих изменений, т.е. задать набор классов. Набор
классов может изменяться в зависимости от потребностей каждой команды, а также
в зависимости от поставленных целей классификации. Каждый класс изменений
представляется изменением графа кода, а, следовательно, и метрик изменений. Для
кластеризации объектов используется метод PCM (Possibilistic C-Means) [5]. Этот
метод предполагает итерационное формирование и изменение центров кластеров. На
каждом этапе минимизируется целевая функция алгоритма путем пересчета центра кластера
и степеней принадлежности объектов кластерам. Декомпозиция данных, содержащиеся
в матрице X на C групп, содержащихся во множестве Q ∈ {q1,q2,..,qi} производится путем корректировки значений матрицы U=[ϻik], которая содержит степени принадлежности объектов
к кластерам μik∊[0;1]. При этом каждый
кластер qi характеризуется
центром vi.
Выполнение алгоритма кластеризации подразделяется на
следующие этапы: инициализация алгоритма, определение принадлежности объектов к
группам по их удаленности от центра, определение новых центров групп, проверка
условия завершения выполнения алгоритма.
Инициализация
алгоритма
предполагает первоначальный выбор количества кластеров и их центров.
Определение
принадлежности объектов к группам выполняется на каждой итерации работы алгоритма. На
каждом шаге алгоритма принадлежность k-го
объекта к i-ой группе вычисляется
согласно выражению:
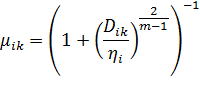
Коэффициент ηi характеризует ширину
итогового возможного распределения и рассчитывается для каждой группы исходя из
средней удалённости объектов от центра группы:
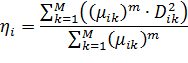
В качестве меры удаленности объектов Dik выбирается косинусная
мера:
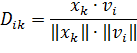
Использование косинусной меры позволяет избежать
влияния масштаба характеристик объекта на конечный результат.
После определения принадлежности объектов группа
производится определение новых центров
групп. На основе определенных ранее степеней принадлежности объектов
группам вычисляются новые координаты центров кластеров:
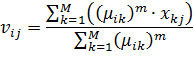
На последнем шаге проверяется условие остановки алгоритма. Если условие остановки не выполнено,
то производится переход к шагу 2, т.е. к определению степеней принадлежности
объектов новым кластерам. В качестве критерия остановки алгоритма выбирается
условие достаточно малого изменения значений элементов матрицы принадлежности U и матрицы центров кластеров V:
![]()
После выполнения процесса кластеризации изменений
можно получить информацию о похожих изменениях программного кода. Далее
информация передается на вход нечеткой нейронной сети. В качестве исходных
данных для нейронной сети служит вектор характеристик изменений программного
кода. Результатом работы сети является отнесение данного изменения к
какому-либо классу изменения и степень уверенности. Поскольку в результате
процесса кластеризации в качестве результата получается матрица центров
кластеров V и матрица принадлежности
объектов кластерам U, то процесс классификации
разделяется на следующие этапы:
1.
Каждый из полученных кластеров vi
предъявляется на вход нечеткой нейронной сети. В качестве результата сеть
указывает степень принадлежности данного кластера к различным типам изменений.
2.
Для каждого изменения формируется степень принадлежности к различным
типам изменений. Это осуществляется путем перемножения степени принадлежности
данного кластера к типу изменений на степень принадлежности данного изменения к
кластеру.
Таким образом, процесс классификации изменений
программного кода разделяется на два этапа – кластеризация изменений
программного кода и классификация полученных групп.
Заключение
Полученная модель позволяет частично
автоматизировать процесс управления качеством программного обеспечения. Применяя
данные методы при разработке программного кода можно получить автоматизированный
процесс сбора информации о дефектах программной системы, а также рекомендации
по их исправлению. Кроме того, при использовании полученных методов повышается
эффективность процесса ручного просмотра программного кода.
Литература
1.
Д. Рутковская, М. Пилиньский, Л. Руктовский. Нейронные сети, генетические
алгоритмы и нечеткие системы. –М.: Горячая линия –
Телеком, 2007.
2.
М. Фаулер. Рефакторинг. Улучшение существующего кода.– СПб.: Издательство «Символ-Плюс», 2003.
3.
Князев Е. Г., Шопырин Д. Г. Анализ изменений программного кода методом
кластеризации метрик // Научно-технический вестник СПбГУ ИТМО. Исследования в области
информационных технологий. 2007. Вып. 39, с. 197–208.
4.
Князев Е. Г., Шопырин Д. Г. Использование автоматизированной классификации
изменений программного кода в управлении процессом разработки программного
обеспечения // Информационно-управляющие системы. 2008. № 5, с. 15–21.
5.
Л. Рутковский. Методы и технологии искусственного интеллекта. – М.: Горячая
линия - Телеком, 2010.
Поступила в
редакцию 11.10.2010 г.