Система извлечения информации из необработанного текста
Манучарян Левон Ашотович,
аспирант Воронежской государственной лесотехнической академии.
В данной статье представлен обзор системы извлечения информации (СИИ), предназначенной для извлечения смысловой и информации из необработанного текста и его представления в виде RDF графов для дальнейших исследований.
Ключевые слова: Извлечение информации, преобразование в RDF графы.
In this article a system for information extraction is presented which enables extracting semantic information from raw text and representing it as RDF graphs for future use.
Keywords: Extraction of information, RDF graph conversion.
Введение
СИИ – это система, основанная на онтологиях, для извлечения и семантического представления структурированной информации из неструктурированного текста, выполненная в виде веб-приложения, которая может извлечь, представить и изобразить предметно-специфическую информацию из необработанного текста в виде сложных (или несложных) связей. Это дoстигается применением алгоритмов извлечения, основанных на правилах, применимых к произвольному необработанному тексту, выявляя ключевые сущности и связи, ссылаясь на определенные фундаментальные знания, которые даны на входе, сопоставляя извлеченные составляющие с базовыми знаниями для достижения логически последовательных результатов согласно заданной предметной области и наконец, представления результатов в виде RDF графов [1], которые могут быть далее исследованы, используя встроенный визуализатор. Кроме внедрения данной новаторской системы для извлечения, проверки/утверждения и представления сложных связей, существуют также некоторые особенности, делающие данную систему уникальной. Некоторые из этих особенностей описаны далее в статье.
СИИ включает несколько рабочих режимов, основанных на желаемом показателе сложности анализа и полноты описания данной предметной области. Так как система основана на онтологиях, она по умолчанию предполагает задание файлов с расширением .rdf или .owl на входе, которые, предположительно, полностью определяют предметную область, данную на рассмотрение. В большинстве случаев это означает, что файл включает онтологию для данной предметной области (классовые концепции и связи), а также ожидаемые в тексте примеры (экземпляры) утверждений. С этим предположением, СИИ работает в пределах описания предметной области, не делая попыток извлечь информацию, не относящуюся к описанию, определенному в заданном файле. Данное предположение довольно хорошо работает в случае с квалифицированными пользователями, обладающими обстоятельными знаниями в своих областях, или для четко определенных предметных областей, которые имеют исчерпывающее онтологическое описание (как UMLS [2]) и глоссарий предопределенных выражений или экземпляров, таких как, например, МЕSH [3]. В этих стандартных настройках СИИ работает, не используя модуль обогащения текста. Однако, во многих случаях было бы нецелесообразно предположение наличия такого всеобъемлющего описания предметной области, имея ввиду присущую сложность корректного моделирования предметной области. Исходя из этого, было принято решение немного отойти от конкретного определения извлечения информации из текста, предоставляя дополнительую гибкость, как описано далее.
Для варианта с частично указанным описанием предметной области, СИИ работает, используя модуль для выполнения обогащений. Для варианта с предположением, что не существует описания данной предметной области, СИИ работает тем же образом, однако на этот раз система ведет себя более гибко, создавая новые связи и понятия из неизвестных составляющих.
§ СИИ выражает извлеченные информационные составляющие в виде множества графов.
Так как выходные данные СИИ всегда согласованы с нормативами W3C для RDF [1], они автоматически становятся описанием графа, который может быть использован любым алгоритмом, ожидающим на входе множество графов. Это делает СИИ ценной платформой для исследований семантических графов при помощи запросов, например для выявления экспертных знаний, система вопросов/ответов, систем анализa оценок, и так далее.
§ СИИ предоставляет расширенный набор функций для визуализации и анализа извлеченных RDF графов, а также возможность визуализации извлеченных семантических графов, используя сервис визуализации от W3C, Isaviz [4]. Вдобавок, система также предоставляет обширные инструменты для анализа, которые могут быть использованы для визуализации частей графа. Это позволяет пользователю анализировать подграфы, ассоциированные с конкретной ключевой сущностью или связью, игнорируя все остальное. Такая особенность становится особенно ценной в случае, когда конечный семантический граф получается довольно больших размеров.
Рис. 1 иллюстрирует архитектурную диаграмму СИИ, которая может быть разделена на три ключевых компонента:
a) служебная система запрос/ответ для обработки служебных запросов от клиента и возвращения соответствующего ответа (регулируемая главным контроллером СИИ);
b) основная система текстовой обработки и извлечения информации (регулируемая служебным контроллером СИИ);
c) система визуализации и анализа, включая часть пользовательского интерфейса (регулируемая визуализационным контроллером СИИ).
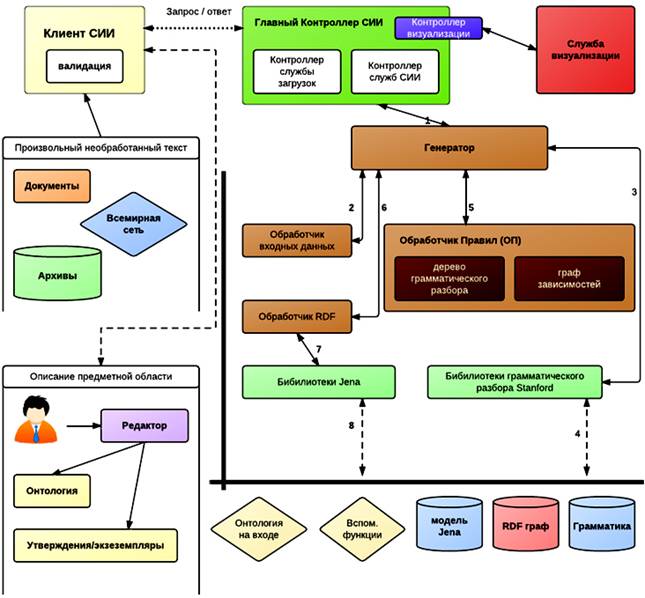
Рис. 1. Архитектурная диаграмма СИИ.
Взаимодействие компонентов СИИ
Конечный пользователь взаимодействует с клиентом СИИ, загружая онтологию, настраивемая желанный уровень сложности анализа и используя текстовый фрагмент для обработки. В общей сложности, в среде СИИ пользователь может:
a) загрузить файл онтологии на сервер;
b) просмотреть ответ в отношении извлеченной информации;
c) визуализировать ответ в форме RDF подграфов.
Каждый из шагов взаимодействия с этими компонентами описан далее.
Загрузка файла.
1. Когда пользователь пытается загрузить файл онтологии, клиент СИИ сразу же посылает HTTP запрос серверу СИИ. Этот запрос перехватывается контейнером сервлетов (servlet – обслуживающая программа, запускаемая при обращении к серверу), который переадресовывает его соответствующему контроллеру (в данном случае, сервису загрузок). Контроллер выполняет загрузку файла, и посылает серверу обратный ответ, в зависимости от того, была ли операция успешно выполнена или нет.
2. Эта онтология остается на сервере, пока пользователь не выйдет из рабочей среды. При выходе, клиент СИИ отправляет другой запрос серверу для удаления файла, который обрабатывается тем же образом, что и предыдущий запрос.
Просмотр ответа в выражении извлеченной информации.
1. Когда пользователь отправляет текстовый фрагмент на обработку, клиент СИИ запускает модуль валидации для удостоверения, что текст отвечает минимальным качественным требованиям для дальнейшей обработки. Данное действие включает базовую валидацию на размер текста, а также кодировку символов. Как только этот этап завершен, клиент отправляет запрос серверу с текстом и уровнем сложности анализа.
2. Этот текст также перехватывается контейнером сервлетов, внутри которого находится приложение СИИ и контроль передается служебному контроллеру СИИ.
3. Служебный контроллер передает запрос генератору, который представляет собой модуль выполнения алгоритма обогащения. Он вызывает входной процессор для обработки входного текста, вызывает Стенфордскую библиотеку синтаксического анализа [5] для генерации дерева грамматического разбора и графов зависимостей и передает эти структуры обработчику правил.
4. Обработчик правил имеет два отдельных модуля для обработки соответственно графа зависимостей и дерева грамматического разбора. Обработчик правил выполняет алгоритм извлечения информационных составляющих для определенного предложения и передает их обратно генератору.
5. Далее, генератор вызывает обработчик RDF, который обрабатывает части валидации и представления согласно соответствующему алгоритму. Обработчик взаимодействует с библиотеками Jena, генерируя новую RDF модель, основанную на извлеченных информационных составляющих.
6. В конце концов, генератор выполняет сериализацию RDF модели в формат XML и сохраняет ее в файловой системе. Генератор также возвращает сериализацию обратно пользователю через HTTP ответ.
Визуализация ответа в форме RDF графов.
Когда Пользователь выбирает этот вариант из меню пользовательского интерфейса, клиент СИИ посылает запрос на открытые службы от W3C. Эта служба позволяет визуализировать хорошо оформленный RDF документ в виде графа. Так как RDF, сгенерированный системой извлечения, соответствует спецификациям W3C, пользователь может напрямую использовать службу для визуализации целых RDF графов. Клиент открывает новое окно со службой и инструктирует пользователю вставить сгенерированные семантические метаданные в соответствующее текстовое поле на странице службы. Следуя инструкциям, пользователь может выбрать вариант для визуализации графов.
Анализ ответа в форме RDF подграфов.
1. Когда пользователь выбирает этот пункт из меню пользовательского интерфейса, клиент СИИ отправляет другой запрос серверу. На этот раз он запрашивает службу визуалиции, и таким образом, контейнер сервлетов передает запрос контроллеру визуализации. Этот контроллер создает визуализацию RDF графа, который сохраняется в файловой системе.
2. С разными сценариаями взаимодействия пользователя с пользовательским интерфейсом, контроллер визуализации отвечает соответствующим образом, который отображается на пользовательском интерфейсе.
Литература
1. Resource Description Framework (RDF). Спецификация RDF - http://www.w3.org/TR/rdf-mt/.
2. Unified Medical Language System, http://www.nlm.nih.gov/research/umls.
3. Medical Subject Headings, http://www.nlm.nih.gov/mesh.
4. IsaViz: A Visual Authoring Tool for RDF - http://www.w3.org/2001/11/IsaViz/.
5. The Stanford Parser: A statistical parser - http://nlp.stanford.edu/software/lex-parser.shtml.
Поступила в редакцию 29.08.2011 г.