Производительность алгоритма кэширования Clock-Pro в информационных системах
Ходаковский Ярослав Францевич,
соискатель Московского физико-технического института (государственного университета).
Введение
В современном мире существует огромное количество приложений, развернутых на всевозможных платформах и серверах, и ежедневно продолжают создаваться и развиваться новые мощные информационные системы. Одна из целей проектирования и отладки приложения – максимально использовать ресурсы системы, на которой это приложение функционирует. Кэш или кеш (от фр. cacher — «прятать») — промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Различают несколько видов кэшей. Низкоуровневый, например, разработанный алгоритм ClockPro был опробован и показал повышение производительности в ядре операционной системы Linux Kernel 2.4.21. Веб-кэш – сохранение наиболее часто используемых веб страниц или отдельного содержимого в течение работы веб-браузера. В данной работе изучается кэш уровня приложения.
Алгоритм Clock-Pro и его реализация
Алгоритм LRU, используется повсеместно наравне с надстройками к нему. В их число входят такие улучшения алгоритма LRU как LRU/2, LRU/k, 2Q. Все они используют похожую структуру, и пытаются получить ту же производительность, использую меньшие ресурсы. По данной теме есть достаточно материала, раскрывающего преимущества и недостатки данного семейства алгоритмов. Поэтому было решено попробовать реализовать и сравнить производительности алгоритмов LRU и другого семейства алгоритмов: Clock. Сама идея Clock – довольно давно известна и тоже широко используется. В основе лежит все тот же список, в данном случае он двусвязный. Новые элементы добавляются до тех пор, пока кэш не превысит заданного размера. В таком случае происходит вытеснение одного элемента. Теперь к объекту добавляется один бит информации - индикатор попадания. Он показывает, обращались ли к данному элементу кэша хотя бы раз. Изначально все элементы попадают в кэш с индикатором проставленным в ноль. Как только какой-то из элементов при очередном запросе находится в кэше, бит проставляется в единицу.
Вытеснение очередного элемента из кэша определяет стрелка, некое виртуальное представление – указатель на очередной элемент кэша. Добавляться любой новый элемент будет на позицию, куда указывает стрелка. После чего положение стрелки будет меняться и она переходит на следующий элемент по часовой стрелке. Если у элемента, на который указывает стрелка, проставлен индикатор попадания, стрелка переходит еще на один элемент, а индикатор становится снова нулевым.
К преимуществам данного алгоритма можно отнести легкость реализации и простоту работы. Однако он требует больше ресурсов, чем LRU и не учитывает частоту доступа к объекту. Тем не менее, этот алгоритм хорош тем, что на его основе можно получить более действенный алгоритм. Как наиболее интересный и новый вариант, для исследования был выбран алгоритм ClockPro.
Основная идея алгоритма заключается в использовании времени повторного доступа вместо времени последнего использования. Когда происходит обращение к объекту, время повторного доступа – это количество объектов к которым обратились между двумя соседними вызовами одного и того же объекта. Каждый раз этот параметр берется как время между двумя последними обращениями. Для удобства назовем этот параметр reuse distance.
Reuse distance используется, чтобы разграничить между собой объекты – разделить на холодные и горячие. Больший reuse distance соответствует холодным объектам, меньший – горячим. Далее все объекты помещаются в один список в порядке их добавления или доступа. Таким образом в начале списка оказываются объекты наиболее давно использовавшиеся, в то время как самые новые идут в конец списка.
Чтобы дать возможность холодным и горячим объектам менять статусы и чтобы убедиться, что статус объекта соответствует его поведению в кэше, при добавлении объекта в кэш он вступает в тестовый период. Если в течении этого периода происходит обращение к холодному объекту, он становится горячим. Если же в течение тестового периода к объекту не было ни единого обращения, он покидает список. Стоит заметить, что если сложилась ситуация, когда холодный объект, находясь в тестовом периоде, должен быть вытеснен из кэша, в кэше остаются его метаданные. То есть остается имя объекта, возможно, какая-то сопутствующая информация, удаляются все его атрибуты, значения и прочая информация. Появляется еще одна классификация объектов – резидентные и нерезидентные. Первые – полноценные тяжелые объекты, вторые – лишь имя объекта, по которому можно определить, был ли он когда-либо в кэше или нет. Так удобно хранить историю доступа ко многим объектам кэша.
Ключевой вопрос – как определять время тестового периода. Если холодный объект находится в списке, и за ним есть хотя бы один горячий после него (с меньшим reuse distance), он должен сменить статус на горячий, так как теперь его reuse distance меньше аналогичного у горячего объекта. Соответственно горячий объект с большим временем повторного использования должен сменить статус на холодный. Таким образом, тестовый период будет считаться как наибольшее время повторного использования у горячих объектов. Если быть уверенным, что наиболее давняя горячая страница находится всегда в конце списка, и все холодные объекты, которые пережили этот горячий объект, прошли тестовый период, тогда тестовый период холодного объекта эквивалентен времени, за которое этот объект пройдет конец списка. Таким образом, все нерезидентные холодные объекты могут быть вытеснены из списка как только они дойдут до его конца. На практике можно сократить искусственно тестовый период и предельное число холодных объектов в тестовом периоде, чтобы уменьшить затраты памяти.
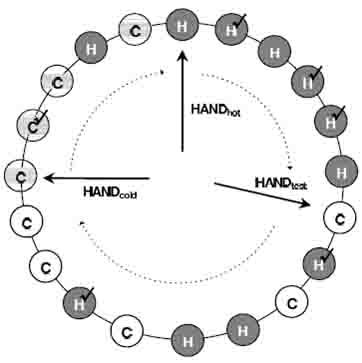
Рис. 1. Схема алгоритма ClockPro.
Структура данных
Предположим, что выделение памяти для горячих и холодных объектов mc и mh соответственно, является постоянным. Общая память кэша в таком случае m = mc + mh. Количество горячих объектов mh , таким образом, все горячие объекты всегда находятся в кэше. Все остальные объекты, к которым доступаются извне – холодные. Среди холодных объектов - mc находятся в кэше, в то время как у остальных (не более чем m) нерезидентных обьектов, в кэше лежит только историю доступа. Получается, всего есть не более 2m записей метаданных для хранения истории доступа.
Как и в кэше Clock, все записи организованы как цикличный связный список. Каждый объект содержит в себе статус (горячий или холодный), реализованный в виде бита. Для каждого холодного также есть флаг (бит памяти), показывающий, находится ли он в тестовом периоде.
В ClockPro логически внедрены 3 стрелки: Hand hot, Hand cold, Hand test . Hand hot указывает на объект с наименьшей давностью использования. Позиция этой стрелки обычно служит порогом времени существования горячего объекта. Любой горячий объект, заметенный этой стрелкой, автоматически становится холодным. Для удобства, будем называть объект, на который указывает стрелка Hand hot – хвостом списка, а объект, следующий за ним – началом.
Hand cold указывает на последний резидентный холодный объект (самый дальний от начала). Так как всегда выбирается именно этот холодный объект для замены, это и есть позиция, откуда начинается поиск объекта для очередного вытеснения.
Hand test – указывает на последний холодный объект, находящийся в тестовом периоде. Эта стрелка используется для прерывания тестового периода холодных объектов. Нерезидентные холодные объекты, заметенные этой стрелкой, покидают цикличный список.
Благодаря исследованиям и полученным результатам, из темы данной работы вытекает новая, не менее интересная для исследования тема кэшей в целом. Теперь к проблеме производительности можно подойти математически. Кэш ClockPro представляет собой автомат с конечным числом состояний. Если рассмотреть все вероятности переходов между этими состояниями, то можно оценить производительность без дальнейшей реализации, принять решение о целесообразности разработки и внедрения алгоритма, увидеть возможности улучшения без написания кода.
Литература
1. Song Jiang, Feng Chen, Xiaodong Zhang CLOCK-Pro: An Effective Improvement of the CLOCK Replacement // 2005 USENIX Annual Technical Conference, pp. 323-336 // http://www.cse.ohio-state.edu/~fchen/paper/papers/usenix05.pdf.
2. A. I. Vakali LRU-based algorithms for Web Cache Replacement // Department of Informatics Aristotle University of Thessaloniki, Greece, 2000 // http://www.springerlink.com/content/bl9gbwk1y0d4d107/fulltext.pdf.
3. F. J. Corbato A Paging Experiment with the Multics System // MIT Project MAC Report MAC-M-384, May, 1968 // http://www.multicians.org/paging-experiment.pdf.
4. S. Jiang and X. Zhang LIRS: An Efficient Low Inter-reference Recency Set Replacement Policy to Improve Buffer Cache Performance//In Proceeding of 2002 ACM SIGMETRICS, June 2002, p. 31-42// http://rigel.cs.amherst.edu/~sfkaplan/courses/spring-2004/cs40/papers/JZ:LIRSELIRSRPIBCP.pdf.
5. Yen-Wen Lin, Hsin-Jung Chang, Ta-He Huang Perfomance Evaluation of ThresHold Scheme for Mobility Management in IP Based Networks // Third Asian Simulation Conference, AsiaSim 2004, pp 429 – 438.
Поступила в редакцию 28.01.2014 г.